I’m back this April as a writing advisor for the second Inkhaven cohort – a month-long blogging residency where residents must post every day or get kicked out. In my more open-ended capacity as a writing advisor, rather than a working coach, I’ve had plenty of free time, and I’ve either done a lot of my own writing OR downloaded and played a lot of a trashy mobile game, for unclear reasons. You’ll never know!
Either way, the residents have been doing a lot of writing. The blogs are, once again, really good. I’ll do a proper round-up post of some of my favorite pieces later on.
If you’re reading this on the day of publishing and you’re in the San Francisco Bay Area, you can come tomorrow (2026/4/25) to the public Inkhaven Fair in Berkeley! A blogging celebration with activities and celebration for writing in general and more specifically our brave residents, only one of whom will be publicly executed for failure to publish.
Some things I’ve been up to while visiting:
I taught a class for writers on ethically clickbaiting your readers. I think this is valuable skillset but very much a dark art – it’s okay if the Inkhaven bloggers learn it, because the stuff they write is good, but I’m dubious about posting it on here, because what if people who write bad stuff read it? What if it falls into the wrong hands? Let me know if you’re interested in this and/or have moral stances about this and I’ll consider sharing it.
Vishal and I learned a lot about a certain prehistoric tree and its current role in society. Watch for an upcoming post plus bonus foray into a new Artistic Medium(TM) for this eukaryote.
I will upload my contribution here for posterity and since it was great fun – though readers should know that I researched and wrote this over the course of a few hours, so it’s goofy and not up to my usual epistemic snuff.
Read the entire zine, as written by Inkhaven residents and advisors, here. Readers should note that other articles in this issue contain a lot of diet culture/weight loss stuff, read with caution.) (I also did some graphic design for this issue.)
IS THE URGE TO HAVE SEX OLDER THAN THE URGE TO BREATHE?
Once I hatewatched a video where someone claimed that the human instinct to have sex is, evolutionarily speaking, older than the instinct to breathe. They then made a lot of other stranger claims but THIS ONE caught my eye because that’s KIND OF EMPIRICAL! The reasoning presumably goes like this: fish have sex and do not breathe. So if you go back in the evolutionary tree far enough that we’re fish, those guys were having sex, so the urge to breathe is newer than the urge to bang. Also, and I am not making this up, something something chakras.
MY HYPOTHESIS:
Our fish ancestors were having sex and not breathing air. But fish do “breathe” by inhaling water through their mouth and letting water wash over their gills, to oxygenate their cells, and they basically have to do it all the time. I suspect this mechanism was co-opted by the later development of lungs so these fish did have the qualia of breathing. More tentatively: I bet this mouth-gill mechanism also predates sex behavior.
The moment of our scientific interest. Illustration courtesy of the inimitable taylor.town
LETS BE CLEAR:
“Sex” in the sense of gametes is really old, probably back to single-celled days. But early animals do other forms of external fertilization,like releasing sperm or eggs into the water en masse, or depositing one and then the other like salmon. We’re specifically talking about internal fertilization by means of genitalia. You know, bangin’. Copulation. To learn more, look up pictures of this on the internet.
Our question here is about qualia, which obviously we cannot “answer.” So I’m going to use a lot of dubious reasoning about evolutionary history to guess. “Dubious reasoning” is, alas, how we got here in the first place. But I am coming out ahead morally ahead of the competition, because I am learning more about fish.
THE OG SEX-HAVER:
As far as we know, copulation was invented about 385 million years ago by a species of placoderm fish named, and I am not making this up, Microbrachius dicki. Its fossils have little arm-type appendages kinda analogous to the ‘clasper’ fins of modern sharks, plus genital shapes that indicate internal fertilization – they probably had sex!1
But then later placoderms might have gone back to external fertilization. Microbrachius was a pretty early placoderm, and the human vertebrate lineage did come out of placoderms (although Microbrachius wasn’t necessarily in the human lineage.)
Later come the sarcoptygians. Lungfishes do external fertilization but coelacanths, to my surprise, are ovoviviparous – which I think indicates some kind of internal fertilization must be happening, because how else does the sperm get into the fish? So we might be looking at an unbroken lineage of sex since the placoderms.
At the end of the day it’s unclear whomst, amoung our fossil ancestors, were bonkin’. Definitely by the time the amniotic reptiles show up, internal fertilization is back on the menu.
Also, qualia-wise, once an animal evolves sex, maybe any later sexual behavior – even if it reverts back to external fertilization – maybe it now “feels like” sex?2 I suspect an evolutionary history of orgasm would be of interest here but that REALLY doesn’t fossilize well.
IS GILLS BREATHING?
What “is” breathing? Humans, and our amniote relatives like reptiles, take air in through the mouth – but most of the ‘work’ you feel breathing is controlling the diaphragm. This moving of the thorax muscles is called “aspiration breathing.”
Fish do buccal pumping, where they move their mouth muscles. Amphibians seem to do a combination of both, breathing in with mouth muscles and exhaling with axial muscles. Note that it’s complicated in fish like lungfish or bettas with various lung-type situations, in addition to their water gills.
But wait, we’re asking about the urge to breathe, right? Whatever muscles you use are secondary to the need to take a breath. …Right? Like, when I’m suddenly scared, I don’t necessarily feel it in my legs or arms, even though that’s the body part I would need to jump up and run away or fight back.
BUT TAKE NOTE:
Humans have more options – a fish needs its mouth open to inhale and closed to push water over the gills. A human has more axes of control.
The fish version of coughing also involves buccal pumping.3
Breathing rhythm is localized to part of the medulla oblongata of both fish and mammals.
Air-breathing fish today use lungs AND gills, and have to switch between them. Some of our ancestors must have been similarly transitional, and also that both kinds of breathing must have had a qualitative difference.
CONCLUSION
It’s hard to know when different things evolved! We actually don’t know for sure which of our ancestors were banging last. We know how breathing worked but not the qualia. I think it’s POSSIBLE that early fish did something qualitatively similar to breathing (pumping water over gills) but maybe not because it had to switch over at some point, and also I guess “urge to breathe in using my diaphragm” and “urge to not suffocate” are potentially distinct.
FUN FACT!
Coelacanths have vestigial lungs. They probably used these for hearing. This is, in my opinion, stupid.
Also see Shadwick, Robert, and Lauder, George (2006). Fish Physiology: vol. 23., Fish Biomechanics (Academic Press.)
Long, J., Mark-Kurik, E., Johanson, Z. et al. Copulation in antiarch placoderms and the origin of gnathostome internal fertilization. Nature517, 196–199 (2015). https://doi.org/10.1038/nature13825↩︎
Look up “oviposition” on human sexuality database “Archive of Our Own” for possible evidence of vestigial human inclinations supporting this hypothesis. ↩︎
Hoffman, M., Taylor, B. E., & Harris, M. B. (2016). Evolution of lung breathing from a lungless primitive vertebrate. Respiratory physiology & neurobiology, 224, 11-16. ↩︎
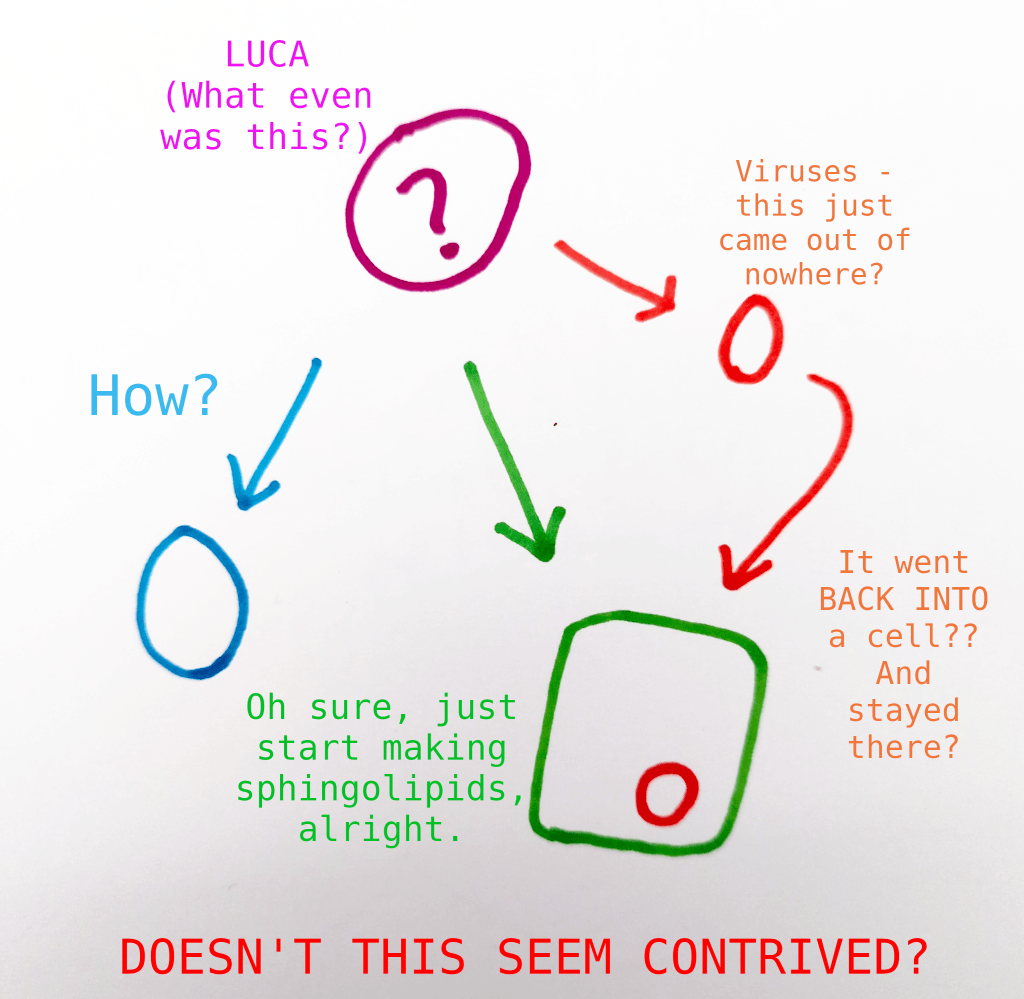
I posit that the last universal common ancestor (LUCA) of all life on earth was a lichen, and that this simplifies a lot of the origin of life complexity. Let me explain why.
All life is, of course, descended from one original organism. The last universal common ancestor (aka LUCA) is just that – the last point on a tree that has any surviving branches today. It’s not quite synonymous with “the first living organism”, but it’s probably close, since life differentiates quickly. It’s probably a single-celled microbe, since all of the early cladistic distinctions (bacteria, archaea, protists…) are microbes, so in the hunt for LUCA, we begin in the realm of cellular biology.
“Mainstream” biology will tell you that this LUCA was an extremely minimal critter, probably sort of a cobbled-together organism that was one of the simpler possible collections of biological systems that could be self-sustaining. All complexity of cellular life developed slowly over time from accumulated random mutations.
The alternate “Lichen as last universal common ancestor” model, which I will refer to for convenience as “Big Lichen”, does not expect so little of Mother Nature.
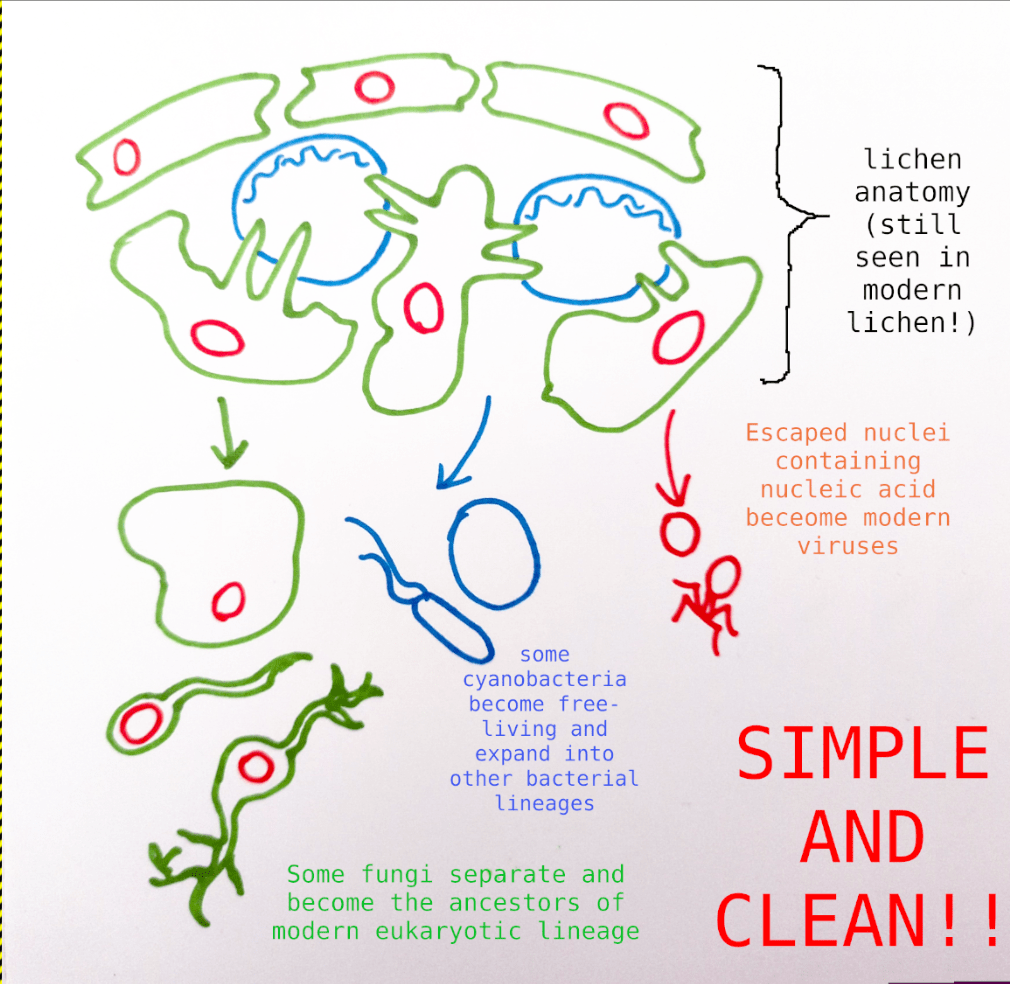
Approved scientific dogma describes lichens as a mutual relationship formed between two organisms: a fungi, plus a photosynthetic organism (which is either a eukaryotic algae or a cyanobacteria). The fungi provides structure and substrate with its protective coat, and it feeds off sugars produced by the photosynthetic component. Thus, they team up – or at least this how it is usually seen.
Under this new framework, I believe it makes more sense to view lichens as an entire organism arriving on the evolutionary scene at the right time, and then fungi and cyanobacteria (or algae) on their own as “diminished” or “partial” lichens – and from these, all other lifeforms descended from them, including our own Animalia lineage.
Setting the stage
For right now, let’s be very clear – any abiogenetic explanation for the origin of life requires several deeply unlikely systems to occur at once. The earliest self-sustaining cellular life necessarily requires a replicating genetic material, a metabolism, and some kind of form or structure to sustain the above processes. Without all of these, the others can go no further. This is a problem for any proposal of abiogenesis, not just ours.
Many lichens are self-sustaining systems, however. Once one exists, all it needs is sunlight and a rock to grow on – the one thing we are certain existed in abundance at the dawn of life. Reproduction and dispersal are explained by the lichen’s ability to flake off of rocks and so spread by mechanical action alone, simplifying another step in its early conquest of the earth.
This “lichen earth” would have, over millions of years, contributed biogenic atmospheric gases and rock weathering, slowly building a vast playground of life with ideal conditions for later evolutionary developments and derived forms.
The days between “the origin of life” and “the last universal common ancestor” are, obviously, very fuzzy, because there is no possible genetic evidence form this time period, and early microscopic life left scant fossil evidence. We’ll address in detail the question of how LUCA-as-lichen itself arose later on. For now, how do we get to the modern earth from this lichen-coated paradise?
A more parsimonious start in the garden of life
It’s much, much easier for natural selection to break a system than to build a new one. 99% of random mutations harm the host, rather than help. Many forms which evolution returns to again and again are simplifications of existing structures rather than adding complexity – streamlined wormlike bodyplans have evolved over and over again, for instance, and that’s in a world where worms already exist. Parasites, often the most simple organisms (since they are able to outsource crucial functions to the host), have independently evolved thousands of times.
Even “productive” mutations are often the result of a complex system breaking down. One classic example of natural selection in action is, for instance, the UK’s peppered moths evolving to be darker in color, which allowed them to blend in better with the soot-covered buildings of the industrial revolution. This mutation is a new phenotype that clearly benefits the moth, of course, but it appears to be caused on a genetic level by a transposon inserting multiple copies of a developmental gene, E.G., a broken virus that has fallen into the gene and misfired. Humans who are able to drink milk as adults suffer from a critical childhood enzyme failing to correctly turn off once they’re no longer weaning. The gorgeous antlers of deer, and the magnificent spiral horns of the markhor, are descended from bone cancers.
“Loss of function” mutations are a major source of evolutionary novelty, and they’re immensely more common than “gain of function” mutations. We assume the early development of the tree of life is littered with these “loss of function” mutants.
Whereas current theories of abiogenesis require us to assume numerous “productive” adaptations randomly generated totally de novo in the early days of life, “Big Lichen” theory relaxes this assumption – more events in early life history are more explicable as “destructive” mutations from the original lichen state.
Terminology
Obviously, Big Lichen theory and the dualist nature of the lichen-organism conflicts with our current, simplistic system, which describes an organism as containing strictly one germline. But chimera offspring are very common, even in animals.1 And anyway biologists can handle, like, the entire existence of archaea, we can manage this one.
Let us describe an organism as a reproducing body containing at least one genome subject to natural selection. This more equitable definition encompasses more than you might think – lichens, for instance, both basal and those that have lost and then returned to lichen-nature (more on this later.) Most large plants are, in an expansive sense, lichens: many rely on a symbiotic relationship with a fungal partner to survive at all. Even humans have a practically mandatory symbiosis with numerous partner microbes for digestion, immune health, and more.
We hope the rest of this piece will be clear despite the obvious “so is a lichen a single ‘species’ or what” issue, but it’s clear that further work in this area will be needed to furnish more holistic and appropriate vocabulary and concepts required to truly describe the lichen-centric model of taxonomy.
How did life differentiate, under Big Lichen theory?
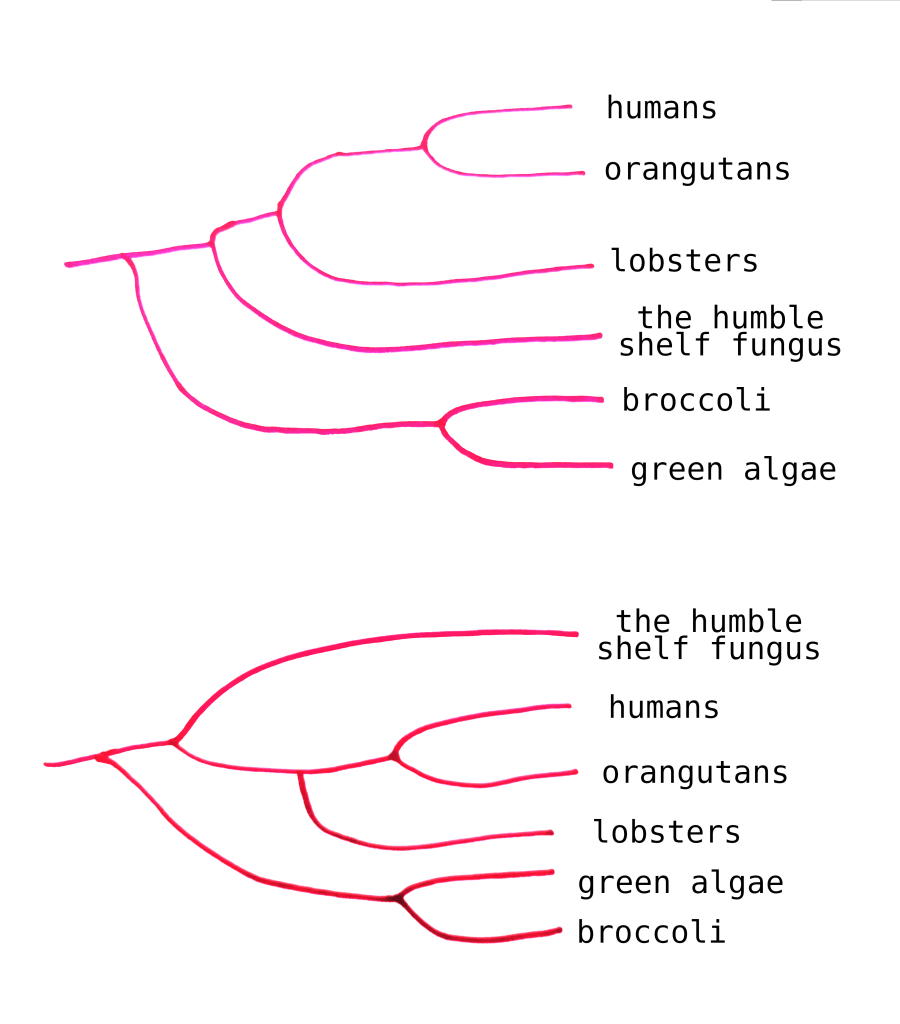
You might know that you can rearrange the specific ordering of a phylogenetic tree. As long as the relationships between the branches stay the same, the order doesn’t matter.
For instance, these two trees convey the same information:
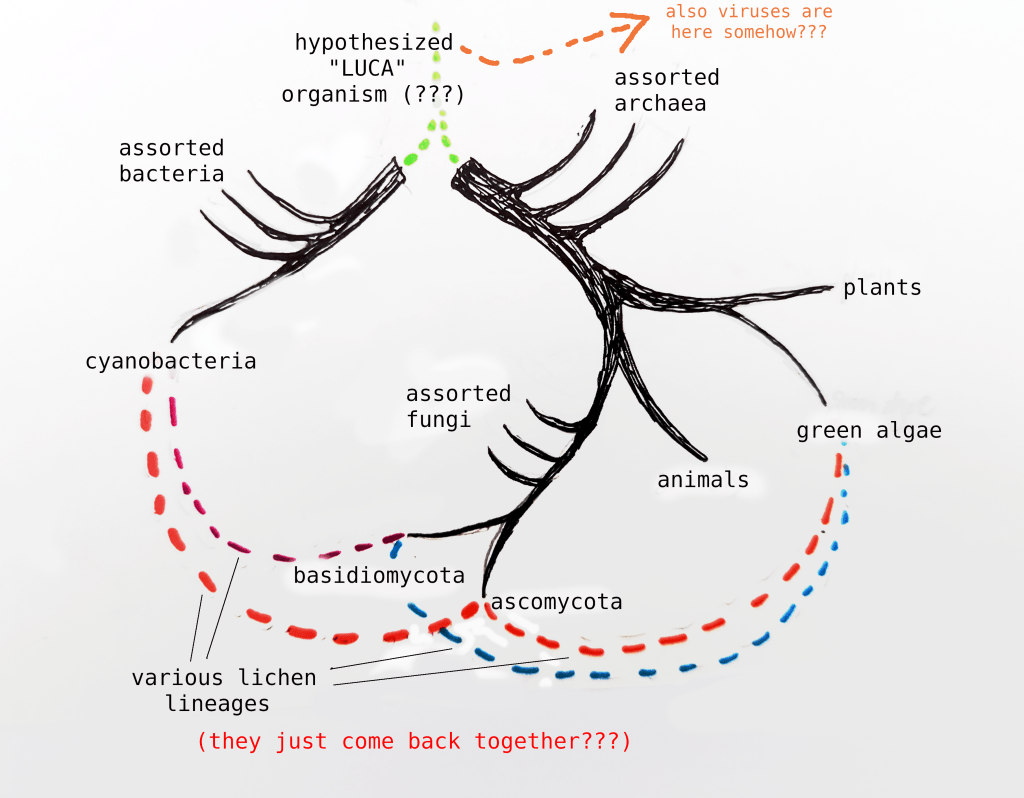
Right? Got that? Okay. We can do a similar procedure to understand the Big Lichen model works. The conventional tree of life looks something like this:
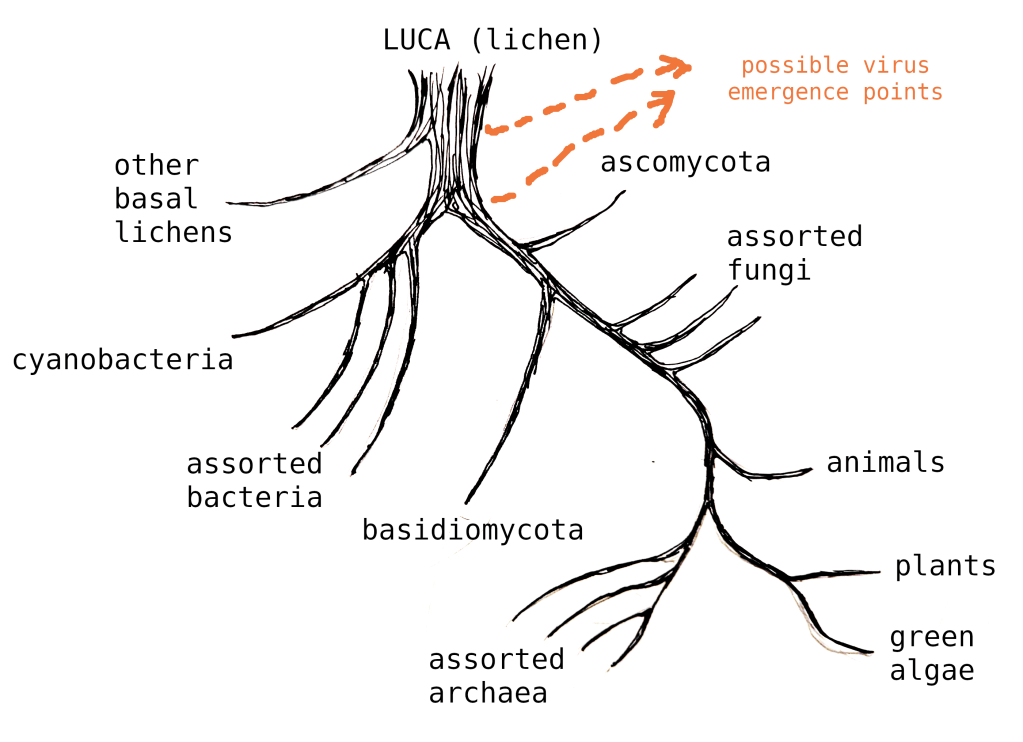
Imagine picking the tree up by one of those lichen lineages. While it’s a little unorthodox, we can actually just slightly rearrange the map to understand the proposed Lichen-As-Common-Ancestor model.
Remember that this is approximate – our understanding of cladistics might change once re-evaluated under the Big Lichen assumption. Also, I could have drawn it wrong.
Thus we eliminate the unknown LUCA organism, and cleanly unite the branches.2
What was the ancestral lichen like?
There are multiple kinds of lichen – basidiomycote and ascomycote fungi, with various kinds of algae and cyanobacteria as photosynthetic partners. While it’s not crucial to the theory, it’s worth paying a moment’s thought to what kind of modern lichen the primordial lichen most resembled.
Most modern lichens – 98% – incorporate ascomycota as the fungi partner, and ascomycota are an incredibly diverse clade. They tend to evolve away from being lichens more than they evolve towards being lichens.3 Since all current statistical trends have been true since the beginning of time, we can surely assume that LUCA included an ascomycota.
I will make a more unusual claim regarding the photosynthetic partner. Some 90% of known lichens incorporate a eukaryotic algae, mostly (but not exclusively) green algae. About 10% incorporate a cyanobacteria instead. I believe that cyanobacteria best represent the older and more primordial state of LUCA – for one, bacteria are vastly diverse and ubiquitous, probably the most numerous organisms on earth; suggesting an earlier point of separation from Big Lichen. Also, while bacteria are often thought of as being straightforwardly “simpler” than eukaryotes, they do have several widespread positive characteristics of their own: peptidoglycan cell walls, nitrogen fixation, quorum sensing, etcetra. So I believe we should expect this broad lineage to appear similarly on, with its own traits, alongside its partner eukarytoic fungi.
Under this model, all eukaryotic organisms are descendants of the fungal LUCA lineage. Many developed their own photosynthetic capacity (possibly at some level due to gene exchange with their original partners) and later returned to partnerships with still-present lichenized fungi. This strategy evidently worked and allowed these eukaryote-eukaryote lichen to spread far and wide.
But where did the first lichen come from?
Sandberg et al (2018) claims that the original development of life is so unlikely as to be at the root of the Fermi Paradox – the reason we don’t see signs of alien life, among all the stars of the night sky, is that life is so unlikely to ever spontaneously develop on a random planet that we really shouldn’t expect it to happen more than once per universe (if at all).4
Big Lichen posits an even more complex early organism. Of course, we don’t know where Big Lichen came from – perhaps there was a vast and diverse evolutionary history before it, of which Big Lichen was the only survivor, and thus came forth all extant life. But I want to defend the remote possibility that the first organism ever to exist at all was some form of lichen.
After all, as mentioned repeatedly, the first living organism was already phenomenally complicated. Another relevant concept is the anthropic principle – the fact that sometimes, the fact that you can observe something at all is itself a relevant piece of information. If it takes lichen to eventually form intelligent life, then the only beings that ever perform this analysis and try to find their roots will have come from the tiny set of universes where lichen developed from nothing.
Further evidence comes from the ALNATS statistical method5. Lichen is, of course, very complex, perhaps a million times more complex then the simplest possible first lifeform. For instance, let’s say that the odds of evolutionarily-capable life developing on a suitable planet are 1 in 10,000,000, and the odds of an entire self-sustaining lichen-type organism with two symbiont partners and all developing on a suitable planet are 1 in 10,000,000,000,000. While one looks astonishingly more likely at first, an ALNATS analysis suggest we really shouldn’t worry about this difference.
Is this all a bit abstract? I’ll try to ground it out. There’s a popular creationist argument about the origin of life that goes like this: imagine you’re walking in the desert and you find a pocket watch in the sand. You note its clear numbers, its useful shape and function, its intricate construction. Is it more plausible that the forces of nature have miraculously refined and eroded rocks to result in this intricate shape and situation, or that someone made it?
And ultimately, I do believe that the evidence for abiogenesis is much stronger than the evidence for god, but I see the point. All theories of life require a bunch of bullshit to happen in order to lead to something intricate and without known precedent taking form. And the added layer of complexity does mean Big Lichen is weak evidence for intelligent origins of life.
The lichen: god’s perfect creation.
But we need not abandon abiogenesis. The watch analogy is good. Of course, it’s phenomenally unlikely that lava and metal deposits and desert winds sculpted a working pocket watch, and it’s phenomenally unlikely that the universe created a minimally viable reproducing system of biological molecules, in pools or deep-sea vents of odd organic chemicals. But the universe is big and life is self-reproducing. It only had to happen once.
Now, in your mind’s eye, just replace that pocket watch with a fully functional television with integrated blu-ray player, currently playing a blu-ray copy of Muppet Treasure Island (1996). All around, the lone and level sands stretch far away. Is it more complicated than the pocket watch? Sure. Is it more unlikely than the pocket watch? Sure. But remember: it only has to happen once.
Last November I had the privilege to be a writing coach at the Inkhaven residency, an experimental month-long blogging retreat in Berkeley, California that attempted to pressure-cook the nutrients, insights, and words out of stellar writers using a simple commitment device: write and publish a 500-word blog post every day, or get kicked out. That’s it.
I mean, there were details. We also fed the participants and provided them with Optional Content, like workshops and visiting writers to consult with and social activities and such. But fundamentally, Inkhaven was there to light a fire.
Sometimes the best way to learn is by doing. You can read books about carpentry all night and day, or you can go out there and build ten bookshelves.
And oh, what bookshelves our bloggers built. Here are a few. I figure if you’re here reading me, you already have good taste, so you might find a new blog to follow among these:
I also really liked less social engineering and more actual engineering for this fertility crisis, please, her objections to the ongoing fertility/demographic collapse discussion – namely, it seems like it’s pretty happy to throw decades of social progress for women under the bus. I’m not entirely unsympathetic to the movement but we gotta have something better than that, and I thought this piece really captured that.
One of my favorite pieces from Vishal Prasad is on computer modeling to figure out why sex evolved and includes some fascinatingly weird-looking models of how relevant strategies might reach equilibrium over time. He also wrote about Agartha, a white supremecist conspiracy theory meme which has in recent times reached a surprisingly multicultural level of abstraction, and I also enjoyed learning about this.
Tomás Bjartur writes a lot of things, including banger fiction. I recommend Lobsang’s Children, a story about a child subsumed by a strange family legacy. Also Rational Teletubbies, which is, and this is the highest compliment I can give a piece of writing, a straight-up fever dream.
He also wrote Gork: The hero we need, an unexpected genuinely hopeful piece about twitter/X’s resident goofy problematic large language model, Grok. This analysis of its social context made me get the value of AI as a trusted public source of information. He explores this more in other pieces – we can certainly improve on Gork! – but this article is a good place to start.
Can’t afford your meds this month? For $20, HP’s AI-optimized healthcare accessibility gamification engine gives you a chance to cover one prescription. There’s even a jackpot tier – all drugs paid for 3 months! HP has already fully funded the insulin medication for over 10 families, and dramatically impacted the lives of thousands more.
As a millennial with ADHD, I for one can’t wait!
Camille Berger wrote some astoundingly beautiful and thought-provoking things. Here’s Burning Utopia, a short and compelling bit of fiction about the possible futures of AI, and here’s That Lying Bitch, a could-happen-tomorrow-sci-fi story about social dynamics and what it might look like when humans lose our edge.
He also wrote Forum Poweruser Forum, a delightful bit of speculative fiction about web forum design. A friend of mine summarized it well when said that he “couldn’t decide if this is horror or pornography.”
Adrià Garriga-Alonso wrote a great and approachable piece on why some of the statistical methods you might have learned in Stats 101 – like the Student’s T-test – are janky fossils from a time before computing was cheap and fast, and how we can easily do better.
Guy at Rival Voices wrote an approachable introduction to jhanas (states of bliss associated with Buddhist meditation, that many non-Buddhists also report attaining) that was well calibrated for the “skeptic killjoy” audience, which is to say, me.
Justin Kuiper examines clickbait, why it works, and considerations in deploying it ethically and tactically. He’s an expert at the youtube game and so has a refined eye for it.
I didn’t read every post published at Inkhaven, and there are many fantastic posts and fantastic authors not included in this little sampler platter. My apologies to those not featured; this is my personal failing. You-the-reader can find them, and scroll through bloggers and posts that might pique your fancy, at the Inkhaven Blogroll.
Cannot stress this enough: literally everyone was good at this.
If you’re reading this on February 28th, the day of publishing, you have the rest of the day to consider signing up for the second Inkhaven cohort this April – that’s right, it’s happening again, and soon! It’ll be in Berkeley California at the beautiful and ergonomic Lighthaven campus.
I won’t be working this one but I will be attending as a writing advisor, so I’ll be around that month and will attempt to dispense guidance and wisdom (if not full time.) Give it a go if you think you can blog with the best of ‘em.
This was an unusually cool sunset at Lighthaven. The sky isn’t usually red there, I promise.
Since I’ll be there but won’t be helping run the show in April, I’ll have more time for actually writing, and I have some upcoming projects I think you’ll like. Supporters help make that financially possible by throwing me a few bucks on Patreon.You could be one of them!
1. In the first really heavy winter storm of the year, your power might go off. This is understandable but you do have to think about it beforehand.
2. If the power’s been off for a while, like, over 24 hours, and then suddenly it comes back on for a few minutes, and then it immediately goes out again – you might understandably believe that that means that the power company is about to restore your electricity, and there was a hiccup but it’s about to come back on for real. Unfortunately, nothing in this life is knowable.
3. The instruction manuals for things – cars, snowblowers, wood stoves, etc – often have useful information about using the thing. A surprising number of my peers don’t realize this.
4. You have a lot of batteries, flashlights, shelf stable food, warm clothes, and drinking water stored, right? Good.
On shoveling snow
5. Snow is easiest to shovel when it’s just fallen. The more time passes, the more freeze-thaw cycles – even gentle ones – build up and make the fallen snow denser and tougher. (This might be less true in very cold places where it never gets above freezing during the day? I don’t know, honestly.)
6. Snow is heavier than you think.
You might think physical strength is useful for lots of things, like overall health or familiar household tasks or picking up dudes (literally or metaphorically.) But actually, the main thing physical strength is useful for is letting you shovel more snow.
Push comes to shove, you can probably substitute grit for physical strength. But I suspect that muscle is easier to build than grit, for most people, not to mention less injurious.
Anyway,digging snow is hard. And snow is the easiest thing you can dig. How do hobby tunnelers do it??
7. Have neighbors up the street with a snowplow. They will save your skin.
8. Speaking of snow being heavy, my Alaskan friend tells me that at some degree of snowfall, you will also want to clear snow off of your roof so that it doesn’t break your whole house. I didn’t know that. Thankfully, my roof survived (for now). There are various tools made for this, one of which is called an avalanche and looks really fun.
(I am further cautioned by a different friend that you gotta wear a hooded coat while scraping snow off the roof, or else snow will 100% fall down the back of your neck. And hey, it’s cold enough out there already.)
On being cold
9. Even if your house technically runs on propane, and you have propane, electricity might still run the propane, so your house is going to get cold. Unless you run the woodstove. Which you will.
If you’re short on kindling, sufficient cardboard CAN be used to light a big log on fire.
10. You should own rainpaints. (Or snowpants. Some kind of waterproof outer layer for your legs.)
11. If it’s too late for that, keep one pair of pants to put on when you go out into the snow for quick trips – and then immediately change into a different pair when you get back inside. This is important for staying dry.
12. Do NOT get wet and cold.
13. You already own gaiters, right? Of course you do. Gaiters are the pinnacle of fashion. Nobody realizes this, but you know that these slick garments can be made in a variety of styles, highlight the calf, and visually break up the block of the leg, adding new intrigue and aesthetic possibilities to the modern conception of dress. You are nobody’s fool, and naturally, you already own a pair of outdoors gaiters.
The situation you find yourself in now is one of the many cases where gaiters are also practical – put them on, go tromp around outside, and suddenly less snow winds up packed in your boot. It’s not a slam-dunk, because when the snow is four feet high it will also top the gaiters – what you really want is rain pants. But it’s still better than not having them, and you’ll feel real good about yourself and your practical, correct clothing takes. Good on you!
14. If possible, live in a house that a Burning Man camp runs out of in the summer. This means that even if the house is otherwise pretty well-stocked for winter storms, you will keep finding manifold useful things along the way that someone stashed in some moment of hurried summer madness, which will now make your time more pleasant – like battery powered string lights, or better shelf-stable food, or hard liquor.
In fact, in the hour of your despair (when you’re out of firewood next to the house, and the rest of the firewood is some 30 feet away but now buried under four feet of snow because you forgot to fix the roof on the woodshed during summer – and see Point 6, “Snow is heavier than you think” – and you’d have to dig your way over there and dig the wood out and then dry it, and you don’t want to do any of that) you will remember that over the summer, someone inexplicably left a garbage can full of firewood next to the truck, sealed under a plastic bag lid, and that’s only 20 feet away AND it’s already dry. You have no idea why that ended up there but in this moment it will give you strength. You can tromp over there and use a plastic child’s sled from the garage to drag wood back to the porch, and thus you will be warm another couple of nights.
On generators
15. You certainly already know: Absolutely do not run a generator inside, or “kind of inside” (open garage, etc), under any structures that contain live people or animals that you care about. This little box loves to make electricity and sparks and carbon monoxide. You must respect it.
16. In fact, any generators you may have around would look just darling in a little structure raised off the ground, with a covered roof, some 20 feet at minimum away from an occupied structure, wouldn’t they?
17. Any generators you might have around should also be checked in the fall to make sure they work, and put away at the end of winter winterized as per the manual instructions. You did that, right? Right? Uh oh.
On water
18. Your house’s well is, of course, also electricity-powered. This adds another layer of complication. You did bleach ten gallons of well water for long-term storage already earlier in the year, right? Good.
Anyway, to flush a toilet without a running tank, dump about a gallon of water right into the bowl as fast as possible. (If you do it slowly, it won’t overfill, but it won’t ‘flush’ all at once either.)
19. Even if you didn’t have plenty of drinking water stored up, you wouldn’t be in trouble, because you can fill a big cooking pot with snow and put it on top of the wood stove. But you do have a lot of bottled water. Good on you.
On morale
20. You might think, at least finally I’ll have time to read one of my many unread books or do one of several arts or crafts I have around. And you will, a little. But it will bring you no joy. You will wish you were playing Animal Crossing.
21. One of the books you’ll read is Shadows on the Koyukuk, a memoir by the son of a fur trapper & a Koyukuk Athabascan native, on his life growing up and living in Alaska in the early 1900s. It’s a great book in any circumstance. But certain parallels will occur to you now, especially. You must thicken your skin to appreciate them. For instance, author Sidney Huntington will recount how he got lost in the woods at night with damp clothes, while it was well under -30° Fahrenheit out, carrying only an axe – so he remembered some advice he’d gotten once, and chopped down some trees, and started two fires to keep him warm and let him sleep through the night until it was daylight and he could find his way home.
Not only is it about 60° warmer where you are, you’ve never even cut down ONE tree with an axe. (Or built a boat, or killed a grizzly bear, or…)
But you must remind yourself that despite your shortcomings, you almost certainly know about more kinds of fish than Huntington did at your age, so modernity has not failed you utterly. And you don’t know anyone who’s ever died from tuberculosis or starvation, which is cool too.
Your ego thus buoyed (in case you needed it), you can find common ground, for instance, about the problem of snow – Huntington mentions how when two people are walking across snowfields in snowshoes, it’s more exhausting to be the person in front breaking the trail. He and his brother would take turns. You can relate to this, now. The second time walking over a path really is easier.
On anabasis
22. While making your little plans, at some point, you will learn – using the threads of cell power you’re able to obtain from the last live power bank you didn’t even know was in the house until you tore through it looking for one – that another storm is due in the next couple days, and that the power company has no ETA on a repair. You will look at your dwindling supply of easily available firewood. You will look at your to-do list:
a) dig out enough space for the large generator, which you think might be more likely to turn on than the small one
b) dig out the truck, just in case
You will look at your two “uh, yeah, I have a blog” noodle arms. You will consider Point 6.
Spend your energy digging the truck out. Throw some clothes inside. Get the hell out of there.
23. You already know that if you’re trying to drive a car over snowy ground, and the wheels start spinning but the car is stuck in place, you need to stop doing what you’re doing right away and try doing something else with the wheels, right? Good.
B: I already live in California. Parts of California are like this.
C: I didn’t mention flushing the toilet by refilling the tank (rather than by dumping water in the bowl) because… I didn’t think of that. It is an extra step because you have to mess with the tank lid, but it has other upsides. Thank you for the advice.
Shout-out to the person who proposed this article was AI-written because a human being would have thought of this. I just asked Claude Sonnet 4.5 how to flush a toilet without running water and he immediately suggested both approaches. No, transformative AI has simply surpassed my personal human capabilities in the area of how to flush a toilet without running water.
D: The tone of this piece is comedic on purpose. I was going to put a note at the top like: “Disclaimer: everything described here is universally applicable” but decided the audience would figure it out. Maybe I flew too close to the sun. But there are trade-offs, you know? Anyway, this is certainly not a full list of advice from a seasoned (heh) expert, just some tales from a person living in a snowy place for the first time who survived the experience.
And you might think “yeah, okay, real nice job with that, dumbass” – but listen, a few years ago, I was living in a not-very-snowy city, with a rare dusting of snow on the ground. And I left my apartment for the first time in days for a stupid little 10-minute walk for my stupid little mental health, and I slipped on a patch of ice on a sidewalk and broke my wrist so badly it needed surgery. So this is a pretty successful winter for me so far, compared to that.
Here’s a game I’m playing with my internet friends in 2026.
This is designed to be multiplayer and played across different regions. It will definitely work better if a bunch of people are playing in the same area based on the same list, but since we’re not, whatever, it’ll probably be hella unbalanced in unexpected ways. Note that the real prize is the guys we found along the way.
The game is developed using iNaturalist as a platform. You can probably use a field guide or a platform like eBird too.
PHILOSOPHY
First, I watched a bunch of Jet Lag: The Game, and talked with my friends about competitive game design using real-world environments. Then we watched the 2025 indie documentary Listers: A Look Into Extreme Birdwatching, which is amazing, and free. It’s about two dudes who are vaguely aware of birds and decide to do a “Big Year”, a birdwatching competition of who can see the most bird species in the lower 48 states. And I thought wow, I want to do something like that.
Nature is cool and I want to learn more about it. But I’m not personally that worked up about birds. Also, my friends and I all live in different places, many on shoestring budgets. So we were going to need something else.
This is my attempt at that: SPECIESQUEST. It’s a deeply experimental, distributed, competitive species identification game. It’s very choose-your-own-adventure – designed so that players can choose a goal that seems reasonable to them and then play against each other, making bits of progress over the course of a year (or whatever your chosen play period is). Lots of it relies on the honor system. It might be totally broken as is and I’m missing obvious bits of game design as well, so we’ll call this V1.
SETUP
There are two suggested ways to play: Local % and Total Species.
In Local %, you’ll try to find as many species (within whatever category or categories you like) as possible, that exist within a specific region you spend time in. I suggest this if you want to get to know a place better.
In Total Species, your goal is to maximize the # of species you observe and record on iNaturalist, potentially within a specific category of interest (herbaceous plants, fish, whatever). I tentatively recommend this if you travel and want to play while in other places, or want to be maximally competitive, or find the checklist-generation process for Local % too confusing.
(It’s pretty easy to switch between them later in the year if you feel like it.)
Local %
To play Local %, you’ll come up with a checklist of all the species known to exist for your region. Only observations within that region count.
The Checklist
First, come up with your CHECKLIST.
You can find a FIELD GUIDE to your area and use everything – perhaps in some given category – as your LIST.
But this is the modern age, and in iNaturalist, here’s how I did it:
Click “Explore” to look at existing observations.
Choose a region. I chose the county I live in. The bigger it is, the more you might have to travel to find candidates. I believe there are ways to create your own boundaries too in iNaturalist, but I’m not certain.
Go to “Filters”. Narrow down the phylum/candidates you want.
E.g. to get to “lichen”, I clicked the “fungi including lichens” box, then I added “lichen” in the description.
I strongly recommend specifying “wild” observations. See the Wild vs Domestic section under Everyone should think about scoring further down.
Select the grade of observations you want to include on your list. “Research grade” will return sightings that very clearly identify the species, IE of species that are really likely to actually be in your area.
Play with these until you have a goal that seems reasonable to you.
Once you have a list you’re happy with, save it. This is your CHECKLIST.
Search your area and identify species over the course of the year.
If you’re in your area and observe a species that’s NOT on your checklist, e.g. there is no iNaturalist existing info about it in that area, you can still count it. You DO have to identify it. That means it is possible to get a score of over 100%.
You can play in multiple categories at once. Just add them up to score. (e.g. if your region has 10 birds and 25 trees, your final score will be out of 35.)
Total Species
Go out and identify as many different species as possible.
Optional: In advance, choose a category to play within. If you’re really interested in birds, this might help you avoid some failure mode like “I was hoping to get more into birdwatching but I keep racking up all these plant identifications because it’s so much easier to find them and they stay still.” You’re playing for the Total Bird Species crown.
Roll your own?
Feel free to choose some other species-counting scoring criteria. Your SPECIESQUEST is your own.
Everyone should think about scoring in advance
Which observations count?
Think about this now. “Clear enough to identify the species” is the general heuristic.
I guess in the birding scene the proof of existence is photos and calls. If you are playing with lichens, probably the call will not be relevant.
“Clear observations on iNaturalist” is a pretty easy one to keep track of.
You can also choose to honor-system it and if you know in your heart that you saw that one dragonfly, that’s good enough.
Wild vs. domestic
I suggest only playing with wild observations. It doesn’t have to be a “native” species – it can be a weed, feral, etc – and I understand that there are edge cases, but try to use “a person did not place this here on purpose and it’s not clearly an escapee from the garden six inches away” as a heuristic.
(But if you’re playing in a very urban area and want to study, idk, trees, you might not have that many, say, wild trees available. Most urban parks are planted on purpose. You can choose something else for criteria – just maybe think about it in advance.)
I really recommend not counting zoos, botanical gardens, pet shops, or other places designed to put a lot of rare species all in the same space. Your SPECIESQUEST is your own, however.
Decide how long your game will last for. You can do a shorter one – or maybe arrange shorter “sprints” within your longer game. I am planning to play over the course of a year.
PLAY
Go out and document some guys.
Note:
People CAN join partway through the session, or dramatically switch their goals. They’ll be at a disadvantage, of course.
SCORING:
Local %
At the end of the time period, everyone determines how many SPECIES on their CHECKLIST they observed. Report your score as a %.
Total Species
Bigger number = more victory.
Crowning Victors
In theory, all the Local % players should be able to compete directly against each other – highest % wins. All the Total Species players should be able to go head to head with others playing in their categories (“Most Bird Species Seen”, etc.)
In practice, probably some of the categories are way harder than others – the choose-your-own-approach is meant to deal with this by letting you set your own limits, but maybe you have a player who is like really into mammals and deems this setback an acceptable price for motivation to go look for mammals, and only identified 4/10 species of weasels that live in their region, but you want to acknowledge them anyhow because that’s still a pretty impressive number of weasels to see, let alone identify. Maybe none of your Total Species players have the same categories. Maybe one of your crew was technically a Local % player but made an impressive showing at total iNaturalist observations over the year… I suggest handing out trophies liberally.
(If you DON’T want to be generous handing out trophies, tailor your SPECIESQUEST league so that everyone is playing with the same ruleset, or something.)
Note:
You can just play on your own, without a league, as a personal challenge.
If you find a species that is unknown to science, that counts for 10 observations for scoring. But you have to be really sure that it’s actually new.
The real prize is the guys we found along the way.
Go out and enjoy SPECIESQUEST 2026. Let me know if you’re playing and/or starting a league with your own friends.
Right now I’m coaching for Inkhaven, a month-long marathon writing event where our brave residents are writing a blog post every single day for the entire month of November.
And I’m pleased that some of them have seen success – relevant figures seeing the posts, shares on Hacker News and Twitter and LessWrong. The amount of writing is nuts, so people are trying out different styles and topics – some posts are effort-rich, some are quick takes or stories or lists.
Some people have come up to me – one of their pieces has gotten some decent reception, but the feeling is mixed, because it’s not the piece they hoped would go big. Their thick research-driven considered takes or discussions of values or whatever, the ones they’d been meaning to write for years, apparently go mostly unread, whereas their random-thought “oh shit I need to get a post out by midnight or else the Inkhaven coaches will burn me at the stake”1 posts get to the front page of Hacker News, where probably Elon Musk and God read them.
It happens to me too – some of my own pieces that took me the most effort, or that I’m proudest of, have zero notable comments or responses. I’m not upset about it. I’ve been around the block. It happens.
Excerpt from dimespin’s essay. There’s more, it’s a great piece, go read it.
This piece is good and even if you’re not a visual artist, you can probably make your own analogies by reading it. That said, to spell out a few for the writerly crowd:
The quick post is short, the effortpost is long
Here is the most important thing I can tell you for writing things that people might choose to read on purpose: Make it short. Everyone has 10,000,000 other things they could be reading. Make it efficient. Make it count.
If you are Scott Alexander, you can get huge readership on your long articles. If you aren’t, try either writing short things or becoming Scott Alexander. Pro tip: One of these things is easier than the other.
The quick post is about something interesting, the topic of the effortpost bores most people
The random historical event you read half a sentence about on Wikipedia and it caught your eye? Maybe that means that it could catch a lot of people’s eyes, and your quick post has brought it to them. If you’ve spend ten years formulating a theory about your field of work, that might only be interesting to people who care about that field. Or it’s about one of those “what is good anyhow” or “my theory of consciousness” type questions that people either already know about or already know they don’t give a shit about. Everyone has their own theory of consciousness, Harold!
The quick post has a fun controversial take, the effortpost is boringly evenhanded or laden with nuance
The quick post is low-context, the effortpost is high-context
The quick posts that aren’t even about a thing you’re an expert in – well, okay, you don’t know a lot, but you’ve written it as a non-expert and it’s at a non-expert’s level of understanding. Most readers aren’t experts in whatever random thing. You are automatically going on this journey of discovery with them.
Meanwhile, it’s really hard to explain something you have a detailed technical understanding of, in a way that’s approachable to others. You haven’t spoken to someone who ISN’T a software engineer in eight months. You’re tripping over feldspars left and right. Even if you try to explain it to a novice, you might not do it very well. “To appreciate why this modern factory design choice is interesting, we have to understand the history of automobile manufacturing logistics. In 1886 – ” Okay, maybe you’re right, but I’m also already closing the tab.
The quick post is has a casual style, the effortpost is inscrutably formal
Excessive linguistic density frequently triggers a distinct reticence in opportunistic audiences to apply interpretive labor to the text in question.
AKA: oh my god, just talk like a normal person, nobody wants to read all that.
You might put formal language into a piece because you are an expert and you’re thinking about it in jargon and conceptual terms. In this case, try saying it like you’d explain it to your buddy who doesn’t know jack shit about it.
You might also use formal language in an attempt to Make It Look Professional – unless you’re aiming for a really particular audience that eats up formality, just stop doing that! Readability is kind.
Look at da Vinci’s works: These ladies with these muscular babies are nice or whatever, but we all know and love the dramatic four-armed man in the circle.
If you’re a writer and you’ve run into this situation and you’re upset about the internet’s bad taste and lack of discernment, my main advice is that on some level, you gotta get over it. You will never have any control over what random people find interesting, or what the algorithms decide to promote, or anything at all about other people. You’re lucky to be getting an audience at all, and if you are, you’re doing at least something right.
If you’re smart, you can convert these flickers of fame into more readership for your other better stuff – but the attention of the internet is best modeled as a random swarm of locusts that will occasionally land on your ripe fields based on its inscrutable whims. You can go crazy analyzing it or you can just keep farming.
Maybe you should just do the opposite of all these things so your writing becomes popular? Well, I don’t know. Maybe, maybe not.
If you care about maximizing readership, I dunno, sure. Clickbait is popular for a reason – it works. If you don’t lie to the readers or advocate for anything evil, then I don’t think you’re doing anything wrong by optimizing for readership.
Note that some topics have inherently wider appeal than others – a short light post discussing something concrete and weird about the world is definitely going to get more readers than a piece that compares different philosophical schools. But if you care about philosophy, maybe the second piece is more important to you to write. The numbers aren’t a proxy for value of the piece or quality of its ideas.
Even if you’re exclusively interested in maximizing reception, audience might matter. I think very few people cared about my 2017 summary of a 2015 Blue Ribbon Study Panel on Biosecurity report, which is fair – I wrote it because I had already read this 83-page-long report, and figured someone else might just like to see my notes. And empirically they did, because a major biosecurity funder came up to me at an event and said they read it and really appreciated that I wrote it – they wanted to know what was in the original report and didn’t want to read 83 pages. This was a fantastic audience for it to reach. Or, like, if you want to contribute to the academic discourse, probably you want to engage with the academic literature, and that’s just inherently gonna dissuade many casual readers.
But listen, I bet you’re not just writing to maximize audience. Friend of the blog Ozy Brennan once said that being a writer requires “the absolute conviction that total strangers should listen to you because your words are interesting and valuable” (as well as “the decision to choose a career where you never leave the house or talk to anyone”.)
You’re here to say something interesting and valuable, right? I don’t think you ought to smooth out everything you touch for the masses. You want to say something that only you could say or that will hit the reader who needs it at the right time. You want to impress that one guy at the Blogging Club, or you practice “blogging as warnings scrawled on the cave wall”, or you’re writing for nice future AGIs creating rescue simulations of you based on your digital text corpus. Listen. Don’t lose your mind about it. Just try to say something beautiful and true. Or, failing that, say something fascinating and baffling.
But, I mean, obviously it’d be nice if the masses turn out to want to hear it too. I get it. There’s nuance.
If you live in this one tiny county in California, you might be more likely to die from Sin Nombre Virus than in a car crash.
In the same way that “why does the frozen spinach I want to buy cost much more than it used to?” engages with a vast interconnected web of economies and monetary policies and farmers and supply chains, asking “what’s up with this rare disease people sometimes get in my part of the world?” is actually a question about the entire ecosystem, plus how organisms even work.
The reason you have to think about the natural world when you do biosecurity is that the vast majority of human diseases come from animals. What we think of as diseases to humans is a two-dimensional slice of a giant, rotating, obscure shape of many dimensions – a whole world of diseases, little communities of microbes and macrobes interacting and evolving and getting sick and occasionally passing their diseases around between them. Communities of parasites built on communities of hosts, all colliding constantly. This is the large scale of biosecurity. Nothing in infectious disease research makes sense without it. Any question about human health or symptomology or individual risk or what have you is a tiny speck on the shore of this ocean.
Occasionally, one of those parasites reaches out of the host community it’s adapted to, and finds a foothold in another host. And so the sphere gets a little bigger, a little more interconnected.
Today we’ll be looking at a single slice of the grand pageant, about this size – one virus in one part of the world, that sometimes slips from its home and finds its way into a human animal.
Sin Nombre Virus
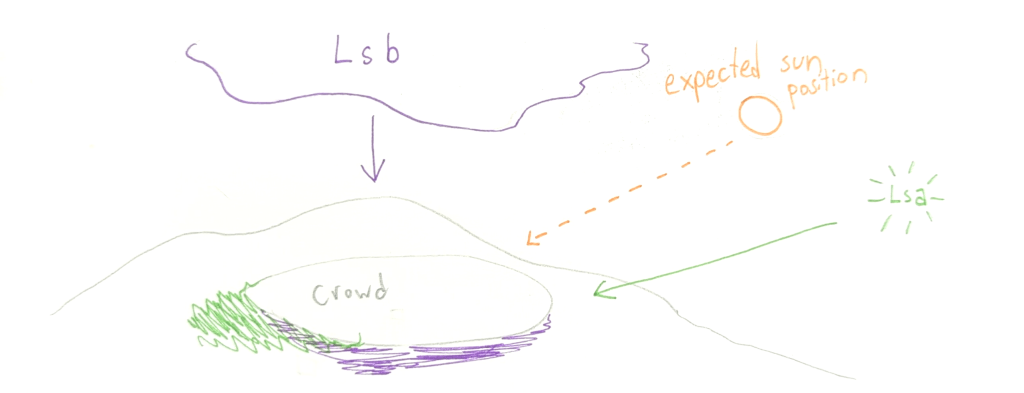
Sin Nombre Virus was first characterized in 1993 in New Mexico. Since then, there haven’t been many identified infections, but every now and then, cases crop up. Even in the medically well-equipped United States, Sin Nombre virus has maintained an astonishing 40% mortality rate.
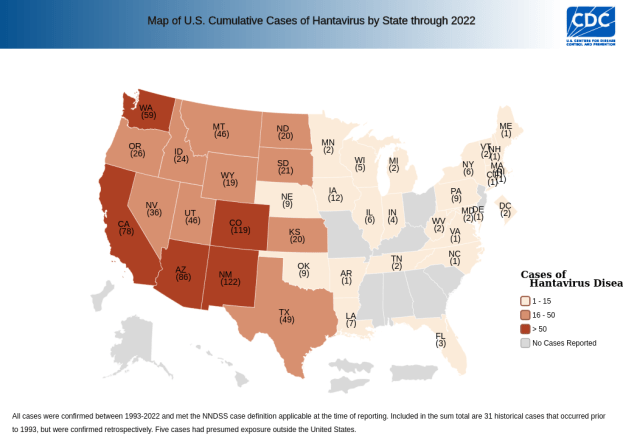
Here’s a map of hantavirus infections in the US by state, since its discovery. We can see that it’s far-reaching, but it clearly has a geographic localization.
So if you live in California, your risk is even comparatively low. But out of curiosity, let’s look closer at a map of SNV infections in California counties.
Huh, what’s the deal with that one county? Note that this is a total case map, not a per capita case map, and that county doesn’t have any large cities. In fact, it’s the 4th least populated out of California’s 58 counties. So the risk is even higher than that map makes it look!
But it’s pretty unlikely that any given blogger would live in that county, isn’t it?
Ha ha, what a funny idea. Anyway, I happened to take an interest in this rare, hyperdeadly disease.
The virus without a name
Most current reporting describes the disease we’re looking at today with the more general name of hantavirus – which it is, but there are multiple human diseases in the hantavirus family.
They’re split into the Old World and New World hantavirus. The Old World hantaviruses cause hantavirus hemorrhagic fever with renal syndrome (HFRS) in Eurasia.
The New World hantaviruses include our subject of interest today as well as the related Andes virus in South America (plus a few other, even rarer North American viruses we’ll discuss later). Andes virus has similar symptoms and is about as deadly as Sin Nombre Virus, but it sees more cases every year – 100-200 versus North America’s “dozens” – and it shows occasional person-to-person spread. We’ll come back to that, but for now, I’m focusing on the most common North American hantavirus because it’s the one that’s in my own backyard. …Potentially literally.
The North American hantavirus we’re discussing today is more specifically known as Sin Nombre virus. Why is it called that?
It was discovered in 1994 after a lot of people got sick in the Four Corners region of New Mexico. Local Native communities actually had stories about odd numbers of people getting suddenly sick and dying during years where the pine nut harvest was good, and indeed, 1994 was a good pine nut mast year. Because of abundant nuts to eat, the mouse population exploded and came into a lot of contact with humans, and enough people got sick and died that USAMRIID and the CDC investigated. And they found a virus at the root.
Ongoing practice at the time was to name newly-discovered viruses after geographic locations nearby the site of origin. But this was already facing pushback – who wants to take a vacation to the scenic Ebola River? On top of that, the area and early cases were heavily Native American communities, and before the disease was shown to NOT be communicable, Native groups were facing racism and shunning over this mystery disease.
The Four Corners region didn’t want it to be the Four Corners virus; the nearby Muetro Canyon was proposed but rejected because the Navajo community didn’t want more stigma (and also Muerto Canyon was named after a massacre against the Navajo), and back and forth, and eventually they just called it the virus without a name, AKASin Nombre virus.
I have some thoughts on infectious disease naming that are too long for the current margin to contain, but I will say that I think this is the kind of cool infectious disease naming schema that you can pull off once.
Mice
This is the western deer mouse, Peromyscus sonoriensis. Sin Nombre virus lives here.
The worst part of biosecurity is having to look at something like this and be like “this thing is the enemy.” Okay, maybe that’s not the worst part.
This is a pretty common strategy of infectious viruses – playing the slow, long game. Humans have a few: cytomegalovirus, herpes simplex virus (especially HSV-1), Human T-cell lymphotropic virus type 1… viruses that lots of people have for their entire lives, and have no idea that they have.
Compare also things like the common cold or human papillomaviruses that cause warts – shorter lifespan and some chance of symptoms but also not much, really. The immune system eventually clears these out in most cases without help, but they have time and means to spread, and they circulate among us and periodically annoy us, but mostly, they don’t kill us.
The deer mouse is not the same thing as the house mouse Mus musculus, which you’re probably more familiar with. But let’s take a minute here.
There’s mice and then there’s mice
We all know Mus musculus – it’s the common house mouse, which has spread worldwide alongside people. If humans build a town, the house mouse will soon follow. There are a lot of less-common related species of mice, like the adorable African pygmy mouse (Mus minutoides).
But Peromyscus sonoriensis isn’t either of these. Technically speaking, is it a rat or a mouse?
Well, what a great question. It’s neither.
Huh, you might think. Mice are on there twice? If you know your way around a phylogenetic tree, you may wonder: maybe the common ancestor was more like a mouse, and it’s rats that are doing something weird?
Ha. Haha. Hahahaha. No. The real situation is more complicated than you could possibly believe.
Rats and mice have evolved multiple times, with some incredibly weird variations in the mean time.
This is the distance between the western deer mouse and the house mouse:
Despite all of this genetic distance, hice mice and deer mice occupy extremely similar niches. Where the western deer mouse is native, it’s completely comfortable cozying up to human dwellings and making its nests inside our big, fancy, warm, dry, food-filled nests.
And deer mice that are widely regarded as the vectors of Sin Nombre virus – the host species that it’s evolved to circulate in. In New Mexico, two studies (one statewide, one in an area where a human was infected) found that about 35% of deer mice had the virus at any given time. Eyeballing it, this lines up pretty well with a “disease circulating stably among the mouse population that rarely spontaneously spills into humans” situation.
…But wait, are deer mice really the only carriers? That second study also found replicating, viable Sin Nombre virus in other local rodents – including the house mouse, mus musculus! The sample sizes weren’t huge, but 3 out of the 9 captured had it!
Note, however, that they only found house mice at one of the sites. There were many more deer mice than house mice. But still, 3/9!
What I don’t know, and what I don’t think anyone knows, is the degree to which hantavirus actively circulates among these other rodents. Are they just getting it incidentally from neighboring deer mice, or do they pass the virus around between themselves too? Is Sin Nombre virus just as at home in them as it is in western deer mice?
The literature is very clear that deer mice are the ones associated with Sin Nombre virus infection. For instance:
The most common hantavirus that causes HPS [that virus being SNV] in the U.S. is spread by the deer mouse.
But “common house mice (Mus musculus), which are prevalent in urban and suburban communities, do not carry hantavirus,” said Charles Chiu, MD, PhD, professor of laboratory medicine in the division of infectious diseases at the University of California, San Francisco.
(Sidenote: this article also quotes one of those New Mexico survey articles I mentioned above, saying that it “found less than 9% of deer mice had the virus.” The study did report that 10/113 deer mice had antibodies to SNV, but it also found that 37/113 of the deer mice had SNV DNA in their system. This is weird, because viral DNA is a sign of an active infection – it’s made by a virus! – but the immune response can linger for a long time after infection, so we’d really expect more mice to have antibodies to SNV than to have SNV DNA. The study does mention that this trend held up across all rodents studied, so maybe this just has to do with the sensitivity of their antibody assay.)
And there are a lot of cases where people got sick, in which the victims knew they’d come into contact with material contaminated by deer mice.
But there are also cases of infection where nobody saw a mouse, and the presence of any mice at all just has to be intuited. Is it possible that Mus musculus is responsible for some Sin Nombre cases in humans?
The public health literature is pretty unanimous about the deer mouse thing, so I’m going to proceed assuming that’s effectively the only way any human gets Sin Nombre virus, but I don’t understand why they’ve ruled out other mice too.
Human
The adventures of a dead-end host
Sin Nombre virus is a transient inside human beings – it’s not adapted here, it doesn’t stay here. We know this because when we isolate the virus from infected humans, it doesn’t easily reinfect deer mice. This suggests that small mutations have to occur to make the virus able to replicate in humans – ones that make it less viable within mice.
[…] which implies that humans are truly dead-end hosts of SNV. Thus, virus evolution is primarily, if not exclusively, occurring in the natural rodent reservoirs.
But SNV can infect humans, and a virus has to replicate to make its host sick. How does it do that?
Well, it’s almost always inhaled from mouse-contaminated material. Then the virus somehow gets into the blood stream.
Once it’s there, Sin Nombre virus replicates inside a variety of human cells, but especially likes endothelial cells and macrophages.
Endothelial cells are the guys that line our blood vessels. They grow everywhere the blood vessels grow, which is to say, all over
Macrophages are a kind of immune cell that devours pathogens. The SNVs are captured by the macrophages, and as with all of their prey, are moved into a lysosome – a cellular chamber that turns into an acid bath, designed to inactivate complex biomolecules (and pathogens they’re attached to) trapped within. But the SNV particles escape into the cell membrane just as the acidification starts.
Replicating inside immune cells is a pretty common strategy for viruses. Sure, the immune cells try to spot and destroy pathogens, but they also end up capturing and moving pathogens around a lot, which can be a big boon if the pathogen has a way to just not get killed by the cell.
Some macrophages roam the bloodstream, but others are concentrated in outposts around the body. Some are in the lungs.
As far as I can tell, Sin Nombre Virus probably gets into the lungs, then infects the alveolar macrophages (and possibly other lung-based immune cells), and then escapes from those into the blood stream where it might infect other endothelial cells. They might also manage to get through tears or thin spots in the alveolar-capillary membrane and get straight into the blood – that’s just a guess.
Replicating in endothelial cells seems kind of overpowered for a virus, right? Like, we have a gazillion of ‘em and they’re all over the body and once you’re next to the bloodstream, it’s an easy highway for a virus to get from one part of the body to a totally different part of the body. to spread from one part of the body to a totally different part of the body – and if you mounted an inflammation or severe immune response, that seems like that would kill the entire host easily and quickly.
And indeed, Sin Nombre Virus does kill its host quite effectively. Ebola, another famously lethal disease, also replicates in endothelial cells. Covid seems to be able to sometimes (in addition to its main habitat in the respiratory tract, an interesting similarity between it and Sin Nombre Virus.)
So is replication in endothelial cells a sure sign that a disease will wreck havoc on the human body?
Well, no. Dengue fever replicates in endothelial cells, and most of its hosts are asymptomatic or mildly symptomatic. Its fatality rate is literally one in a million. And moreover, cytomegalovirus is an endothelial replicator. Like we talked about before, cytomegalovirus of those viruses that’s almost a commensal – most people have symptomless cytomegalovirus infections. (It can cause disease in unborn fetuses, infants, and the immunocompromised, and seems to contribute to cancer risks down the line – it’s not great – but, again, most people have it.)
Also, lots of viruses attack tissues that are essential and would be bad to call the full attention of the immune system to – herpes viruses (another near-commensal genre of virus that most infected carry without any symptoms whatsoever) infect nerve cells, for instance. Lots of viruses infect the lungs, which are famously important, and some of them kill you and some of them are no big deal.
So I think a general lesson here is that the driver of virulence here has more to do with the rate of growth / level of viruses active at once and the degree to which they activate the immune system, not the infected tissue.
Do a bunch of people within the regions where it is have indications of asymptomatic or past infections?
This is a great question. After all, mice have it quietly, and people seem to have the capacity to carry or fight off a lot of infections quietly without notable symptoms. Are we sure this isn’t the case for hantavirus?
Well, so far as I know, nobody has checked.
Wait, can we talk about the actual disease?
Yeah, fine I guess.
According to the CDC, the early symptoms of Sin Nombre virus disease in humans – AKA hantavirus pulmonary syndrome (HPS) or hantavirus cardiopulmonary syndrome (HCPS) – emerge 1-8 weeks after acquiring the virus. They start out, like a lot of fucked up viral diseases, with generic symptoms:
Muscle aches
Fever and chills
Malaise
Headaches
Abdominal pain
Though “aches” might be a standout. University of Colorado Health (Colorado has a lot of SNV cases) reports that severe muscle aches, especially in the back and lower extremities, are a common hallmark of HCPS cases. (Hey, I got severe leg pain when I got shigellosis on purpose too – shigellosis, much like Sin Nombre virus, is an infectious disease that notably does not target the legs. What’s up with that?)
4-10 days after this, the cardiopulmonary stage of disease begins, AKA “the part that kills you”:
Coughing
Shortness of breath
Fluid buildup in lungs/chest
Tachycardia
Arrythmia
Cardogenic shock
Respiratory failure
HCPS has a 40% death rate. Deaths occur 24-48 hours after the start of the cardiopulmonary phase. There is no vaccine or known effective antiviral.
Buying time
If you get HCPS and reach the cardiopulmonary stage, the thing that will save your life is a medical technology called extracorporeal membrane oxygenation (ECMO). An ECMO device draws large volumes of blood out of the body via inserted tubes (called cannulae), runs the blood through an artificial lung (called a membrane oxygenator) to remove carbon dioxide and reoxygenate the blood cells, and puts the blood back in the body.
HCPS seems to be one of those diseases where the body can rally and fight off the disease, if it has enough time. I attended an online lecture delivered by clinician Dr. Greg Mertz and this is the sense I got: SNV doesn’t permanently damage the heart and lungs, it just overwhelms them. If ECMO takes over while the heart and lungs are out of commission and keeps plenty of oxygenated blood in the system, the immune system can finish the job and the heart and lungs can go back to work afterward.
If you go to a hospital with symptoms and they make a presumptive diagnosis of HCPS, you can opt into having the ECMO cannulae inserted in advance – they won’t start ECMO until you go into shock (because your heart/lungs fail), but if you do go into shock, they’ll be able to start re-oxygenating your blood immediately. At this point, doing this changes your odds of survival from 50% to 80%.
(I see that in my notes from that talk, I also wrote “Do not go into shock”, as it leads to “DEATH V FAST.” So if you get to decide at some point whether or not to go into cardiac shock in general, try not to.)
So if you think you’ve been exposed to SNV and 1-9 weeks later you start experiencing arrhythmia and shortness of breath, proceed straight to a hospital with an ECMO device.
ECMO devices are not extremely common. You can find out which hospitals near you have ECMO devices on the Extracorporeal Life Support Organization website. If you happen to be reading in Mono County, your nearest ECMO is probably in Reno Renown Regional Medical Center.
…But if you’re one of the 12,000 residents of Mono County, then yeah, probably. Mono County has had an unusually high 3 HCPS deaths from hantavirus this year, so you have a 0.025% chance of dying from HCPS.
You might actually be more likely to die from hantavirus as in a car crash (0.012% chance in any given year.)
(Sidenote: Naively, I’d expect Mono County residents to have a 0.000004% of dying by being struck by lightning like anyone else, but if you actually look into it, Florida specifically and the southeast generally have a really disproportionate number of lightning strike deaths. We should probably stop rhetorically treating getting struck by lightning as an entirely random act of god and start thinking of it as a physical event with contributing factors like everything else.)
Questions
Why is the geographic range of hantavirus infection so limited?
Let’s go back to that map of USA state-level infections.
So mostly, that makes sense. But how are there ANY cases in the east half of the state?
SNV’s weird siblings
Those other HCPS cases on the east coast? Well, they’re not (or at least, not only) people who happened to travel from the West Coast, and they’re not (or at least, not only) far-ranging western deer mice.
Those are the work of other, rarer hantaviruses, carried by other rodents, spilling over occasionally into other humans in the same way, causing HCPS, and with about the same fatality rate.
Each of these is really rare, even rarer than SNV. But that’s odd in and of itself, right? Like, do all of these host species just interact less often with humans than deer mice in the Western US? Are the viruses less common in their hosts, or even less transmissible than SNV? The answers might be out there, but I don’t know that they are.
I ’m also curious about the California county-level breakdown: why Mono County? (And note that this is raw cases, not cases per capita – Mono County has a tiny population.) Is it because there are more deer mice? Or is hantavirus localized to certain populations of deer mice?
Well, here’s this other data on seroprevalance of hantavirus among captured mice in various counties. Sure enough, Mono County has the highest seroprevalance, at 31%, but apparently 25% of tested mice in Santa Barbara County also had SNV, and Santa Barbara has a lot of people in it!
So why does Santa Barbara see very few human cases, while Mono County has a lot?
Here’s my guess at why: it has to do with the houses, and it has to do with mice. Mono County has a lot of barns, sheds, and vacation houses that are left empty part of the year. The classic situation where a person gets SNV is cleaning out a shed or outbuilding that’s been inhabited by mice, kicking up a lot of mousy dust and particles, and inhaling SNV. A shed or a building that’s left for the summer or winter is a nicer place to build a shelter than under a bush, but it’s still not that cozy – it might not have food inside so the mouse still has to forage a lot, and it might get very cold or very dry. There might not be many other buildings nearby. A region-adapted, mostly-wild deer mouse, is going to have a better go in an outbuilding then the urban Mus musculus – and indeed, every mouse I’ve seen or caught around my home has been a deer mouse.
Santa Barbara County is much more urban and has a warmer climate. I bet the mice that people encounter there are almost all Mus musculus. I bet all the Santa Barbara deer mice live in the wild, outcompeted in cities by the larger and more urbanized mus musculus.
And the deer mice are god’s chosen carriers of SNV, and the Mus musculus aren’t. It’s just a deer mouse disease. So it’s much more likely to crop up where people interact with deer mice, and they do so a lot more in these rural, more-wild environments.
It’s an apparent puzzle that makes a lot of sense once you just ignore the human health angle for a second. SNV is a deer mouse disease that circulates among deer mice. Think about which mice want to live where. Humans, as is often the case, are providers and users of nests, and otherwise, are only relevant incidentally.
But wait, can we check this?
If my model is correct, areas that have high SNV caseloads will:
Be mostly rural (probably without major cities?)
Have extreme climates
Have a lot of outbuildings, plus homes that are inhabited seasonally
It would also be interesting if they’re clearly geographically clustered – like if specifically one part of the world is a hantavirus hotbed.
Yeah, let’s look at some other states that get a lot of SNV cases. I don’t expect to get great data at anything lower than the county level. Colorado and New Mexico both get more SNV cases than California, and have county level data.
I tried to look into this further, and ran into kind of a dead end. Or maybe I’m just wrong.
The counties with the highest rates include La Plata and Weld counties in Colorado, and Mckinley county in New Mexico, which is such a standout that it dwarfs the others.
La Plata County has a population of 55,638 with the largest city (Durango) at 10,000. It has some parks and overlaps a national forest, no major ski areas.
Weld County has several cities and a population of 329,000. (It contains parts of some large cities that are on the border so it’s hard to break down for sure, but a lot of people live here.) Okay, not looking great. It’s fairly flat with some mountains, and mostly farming country.
Mckinley county has one city of 20,000 and no other cities, but a lot of smaller towns and census-designated places and such. Its total population is 73,000, which is pretty big! I can’t find indications that it has a lot in the way of seasonal dwellings – there aren’t many ski resorts. The county does seem to be pretty dispersed, housingwise, which might imply more outbuildings.
So, uh, none of this actually cleanly supports my mode, but it’s not necessarily evidence against it either. We might just need data on which kinds of mice are common in human dwellings in these areas, and how common mice are overall.
What makes Andes virus infectious interpersonally, and SNV not?
It seems like ANDV builds up in the salivary glands of humans, and saliva is its mode of transmission. SNV doesn’t do that.
SNV collects in the lungs and heart. ANDV collects in the heart, lungs, and salivary glands, and tests studies have indicated virus in fluids from both of these. It seems to spread via saliva, droplets, and aerosols. Sex and close contact are major risk factors. Otherwise, ANDV has a similar features and fatality rate to SNV.
Saliva also seems to be how deer mice spread SNV and ANDV among each other – both of them show up in the salivary glands of their host mice, but only ANDV inhabits human salivary glands.
(If we could somehow prove that ANDV could spread from the lungs, well, that would suggest some new mechanism also in play – but that seems hard to test, given that the mouth is, you know, between the lungs and the rest of the world.)
That said, I actually don’t understand why ANDV isn’t airborne, or otherwise transmitted from the lungs. The mousy particles that infect humans seem to be from kicked up dust and such, so there’s reason to think it could be aerosolized – maybe the virus particles don’t escape the lungs very well?
That’s all the things I know about Sin Nombre virus, plus some things I don’t. Let me know if you have the answers. In the mean time, don’t die of cardiopulmonary shock. I, for one, am doing my best out here.
The Miracle of the Sun at Fatima was a 1917 event predicted by several children who said they were visited by the Virgin Mary. Thousands of people showed up in the field in Fatima at the predicted date, and witnessed odd celestial phenomena. It was validated by the Catholic Church as a true miracle.
Accounts are not unanimous, but witnesses generally reported the sun as moving around, changing colors, and “spinning” in the sky.
This has a couple interesting features: It was documented at the time and many thousands of people were there, and later gave their eyewitness accounts – and it was photographed by journalist Judah Bento Ruah for the Portuguese newspaper O Século (“The Century”).
The sky does not actually show up in the photos, which is expected – photographing the sun was especially hard in 1917, and Ruah didn’t show up expecting the sun in particular to be doing something weird. (Nor were the pilgrims – they were expecting a miracle, but didn’t know what it would be.) Ruah’s photos, first published soon after the event, sure do show a lot of people gathered in a field, staring rapt at the sky.
Dr. Phillipe Dalleur analyzed these, and wrote a paper (“Fatima Pictures and Testimonials: in-depth Analysis”, Scientia et Fides, September 2021) arguing that these photos indicate that the light source in the photo corresponding to the observed sun is at about 29°, not at the expected solar angle of about 40° – so it’s concrete evidence of a true miracle, right?
More recently, Ethan Muse at Motiva Credibilitatis uses this point to argue the same. Muse and Dalleur points to other aspects of the event too – e.g. even if the apparent odd behavior of the sun was due to really weird meteorological conditions, how were the children apparently able to predict that? What were the people seeing? What were the children reporting?
See e.g. Evan Harkness-Murphy at The Magpie for possible explanations for some of these other attributes that do not require supernatural explanations.
But as a woman with a fondness for A) very concrete claims of unexpected phenomena and B) OSINT, I’m only going to be looking into the angle-of-the-sun thing.
Because I do agree that if these photos showed that the sun was at an odd angle, that would be evidence for a miracle. The photos were first published days after the event, so while there were ways to doctor photos at the time, they would have had to have done it quickly. The photos were taken by a Jewish journalist who did not have a clear motive to fake evidence of a Christian miracle (attributed to the Virgin Mary). Lots of people corroborated the date and approximate time of the event, and the sun is, of course, one of the most reliable physical phenomenon there is. If that can change, maybe it has to be God doing it.
But I read Dalleur (2021) and I’m really not sold that the photos indicate anything celestially weird going on.
Dalleur’s data
Most of Dalleur’s argument comes from one photo, listed on the Shrine of Fatima website and in his paper as D115. It’s this one – we’ll be referring back to it a lot.
I’m going to ignore the part in Dalleur’s paper about the dry parts on the clothing. I think it’s explainable by conventional means. People don’t necessarily stay at exactly the same angle for long and shift around, and might be uncovering and covering themselves to dry off after being rained on at idiosyncratic angles. I don’t think this tells skeptics much about the light source.
Dalleur has clear photos; we don’t
A lot of Dalleur’s argument has to do with shadows in the photographs. The shadows are really faint, which is what we’d expect – everyone agrees that it had recently stopped raining, so the sky is cloudy and the lighting is diffuse.
The public photos of these photos are low-resolution and do not really show shadows. Dalleur obtained high-quality scans of these photographs from the originals at the Shrine of Fatima. These versions show the detailed shadows Dalleur is using for his analysis, and as far as I can tell, aside from cropped excerpts included in Dalleur’s paper, these higher-resolution versions are not available online.
Compare what sure looks like the shadow of this cane in Dalleur’s version, to the enlarged version of the photo I was able to download from the Shrine of Fatima’s website. You can’t really tell there’s a shadow in the lower-res public version.
Left: Excerpt from Dalleur (2021). Right: same version from publicly available version of the photo.The shadow in question. Like, it’s faint either way, but it looks like a shadow on the left and I’d be hard-pressed to tell that it was anything on the right.
More shadows would be really useful for analysis. (I sent Phillipe Dalleur an email asking for the full versions but haven’t heard back yet.) It would be much easier to evaluate his claims if these were available.
In short, if you have a photo with an object lit by the sun and casting a shadow –
Where the casting object is roughly vertical
Where the shadow is cast on level ground
And…
You know where the photo was taken
You know what date the photo was taken
You know vaguely what direction the shadow is pointing
…Then you can tell what time the photo was taken.
If you have other parts of this information, like you do know the time, you can also tell e.g. where the photo was taken, or at least narrow it down to certain parts of the world.
In this case, we know where, when, AND what time the photo was taken – at least roughly. Our question is whether all of this information lines up the way we expect. If the shadow looks different, then the light source must be different, like, say, if the sun or a sun-like object is moving miraculously around the sky.
But alas, there is no shadow in these photos that meets these criteria. This isn’t surprising. Everyone agrees that it was raining shortly beforehand, so the sky was still cloudy and the lighting was diffuse. (Also, again, the publicly available photos are so low-quality you can hardly make out any specific shadows at all.)
All of this is to say that Dalleur has to use much more complicated methods to estimate the sun’s angle, and I see why. There aren’t good shadows for the simpler method described by Waters.
I just don’t think the methods he used instead are good enough to draw the conclusions he draws.
Are there really two light sources?
First of all, Dalleur’s argument includes an assumption that there are two light sources casting shadows – the light source corresponding to the thing the witnesses identified as the moving sun (“Light source a” AKA Lsa), plus a diffuse, higher-up light source, probably sunlight bouncing off and/or filtering through a cloud (Lsb).
Dalleur’s proposed setup.
A quick note – I grew up in Seattle so I’ve experienced plenty of overcast and weirdly-sunny-sort-of-overcast days. I don’t remember seeing a double shadow under these conditions. I can’t rule it out, and of course Dalleur isn’t claiming for certain that Lsa is the sun or works just like the sun, but I wouldn’t go in expecting a double shadow in these conditions.
In any case, Dalleur only points out one example of a double shadow, cast by a rock on rocky ground. (Left, below.) While the excerpt does look like a double shadow, it could also be the shadow of the rock next to it, or the ground color, or water from the rain that hasn’t dried yet.
There’s also an example of the two light sources cast on a curved umbrella handle (right, below), but the “separation” between the two light sources could be a darker part on the wood of the handle.
Like, it’s just the rock. I guess all I’m saying is that if you assumed there was only one shadow cast, and evened out Lsa and Lsb, that would look more like one light source higher in the sky (more like the expected location of the sun.)
Like, these would look pretty similar, especially if the shadows weren’t clear and all you had to go from was one old photo.
I’m unclear to what degree these are explicitly built into the final analysis that gets us to the final 29°-Lsa-angle number. Dalleur looks at 4 shadows and as far as I can tell, only one of them (this rock) features a double shadow.
In any case, Dalleur spends time on the “two light sources casting shadows” thing and I’m not sold based on the example given.
I’m pretty sure there’s too much assumption to make the math reliable
First of all, here’s a (angle-accurate) sketch of the situation in question. According to Dalleur and to live testimony collected by John de Marchi in “The True Story of the Miracle at Fatima”, the miracle takes place for a few minutes somewhere between noon and 1:30 in solar time, Fatima, Portugal, October 13 1917. so according to SunCalc.org, the sun should be at a solar altitude of 39°-42°. Dalleur agrees. He suggests that the apparent “sun” (his Lsa) angle in the photo he analyzes is 25°-32°.
To be clear, if this were true, astronomically, this would be bananas – the sun is so reliable that if we had a good piece of evidence that it had been anything else (say, there were a sundial on level ground in the photo that clearly had an incongruent shadow) we should be very surprised indeed. But I show you this drawing so you get a sense that we’re not dealing with, like, a hugely different angle, especially as estimation error comes into play. Which it will.
As far as I can tell, the main argument about that 29°-angle comes from photo D115 (the same photo we’ve been looking at so far) and some math about photo optics and what “pitch” and “roll” angles the photo was taken at.
I can’t pretend I totally understand or can replicate the math used. But I can tell there’s a lot of estimation. (See around Figure 10 and 11 in the paper.)
Figure 11 from Dalleur (2021). Featuring: More optics than I know what to do with. Sorry.
While not every estimate used is spelled out, it looks like Dalleur estimated:
Where the obscured horizon is
the height the camera is at
how far the camera seems to be from the reference points
hanging thread from some of the clothing in the photo, although we’re not sure what and he acknowledges that some other hanging thread on a different person is at a different angle (because of wind)
The camera being correctly leveled every time, even though we’re told Ruah was moving the camera and taking pictures at an incredibly fast (for 1917) rate of one per minute
the slope of the ground
angles of the 4 shadows indicating the direction of Lsa (more on this soon)
The focal distance of the camera, which was set manually by the photographer and which is estimated partly by using a reference for what good photography practices at the time were.
Even if the math comes up as putting the sun at a ~29° altitude, I’d be shocked if there’s not enough error in there to account for a possible 8% difference in actual solar/Lsa angle.
Also, those shadow angles are sus
As best I understand it, the shadow angles are the really important part of this calculation. The whole thing hinges on those angles being unexpected. But we’re looking at total 4 shadows, none of which are cast on level surfaces, and some of which I don’t even think are cleanly cast shadows indicating the direction of Lsa. For 3/4, Dalleur does not indicate what he thinks these angles are.
One of these is the double-shadowed rock from before.
Another (bottom right of the above image) is, apparently, another rock. I don’t even know what precisely I’m looking at here. But it doesn’t look like it’s cast on a level surface. That angle is going to drastically effect what angle the shadow seems to be at.
Another is the hand of the boy on the left side of the photo, and again, I’m not sure what I’m supposed to be gleaning here or what Dalleur thought that angle was. Is it the shadow of the pocket on the thumb? Thumbs are curved! His hand might be angled!
Another is on this hat.
Look at that line 4 on the top of the hat.
To me that could easily be the fold on the “bowl” of the hat, and not something that would tell us much about the specific angle of the light source. And either way, it’s cast on the “bowl” of the hat, which we wouldn’t assume to be flat or level.
I think someone with more patience for trig than me, or better yet, experience with Blender or another 3d modelling software, could take a crack at this more definitively – like, setting up this scenario with some models and playing with the angles and light sources (Blender can definitely simulate one diffuse light source vs. two light sources at different angles, etc) and seeing what looks most like the shadows in the photos. I expect the shadows in the photograph will be totally in line with natural phenomena and the natural position of the sun.
Thanks for reading – this is a post a friend encouraged me to hammer out. I’ll link his related analysis when it’s up. I’ll be back to biosecurity soon, I promise. I have a freaky virus to tell you about and everything.
Art has died and been reborn a thousand times now. Join me at its graveside once again. Let us speak a few words for what once was. Let us imagine the inconceivable and hollow future ahead without it. If you weep, I will pass you my handkerchief. And let us all pretend to be surprised once more when it bursts out of its coffin, on fire, and singing.
Do you know what song it sings this time? I think you do.
Skibidi Toilet is a wildly popular animated video series. Particularly, it is popular among the youth. Most millennials-and-above I’ve talked to go glass-eyed when its name is invoked. Their souls momentarily leave their bodies, but float back down again in short order. “Why?” they ask, laughing. “Why would you watch that?”
And it’s not completely naive. There’s always been vapid absurd art popular among kids, and wise adults remember and know this. On the internet, it’s stick figure fights and zombocom. Saladfingers and Badger Badger Mushroom. Baby Shark and those weird Spiderman Finger Family Dancing Elsa Learn Colors videos.
Skibidi Toilet is different from all of those. Skibidi Toilet is, like, actually okay.
At time of writing, the series stands at 26 seasons and 78 total episodes – but most of the episodes are under a minute long, so it’s only 2.5 hours total. Created by DaFuq!?Boom!, AKA Alexey Gerasimov, Skibidi Toilet is a serial narrative about the unfolding conflict between two groups: the Skibidi Toilets, which are human heads that come out of toilets, and what I think of as the AV Army – humanoid figures with cameras, speakers, televisions, and so on for heads.
The AV Army is completely nonverbal. The Skibidi Toilets sing, but only the one song, incessantly. There is extremely little verbal or written language throughout the series. Even “skibidi” is a nonsense scat word. (It’s been speculated that this has to do with why the show has been so popular with children, and with international audiences. Is that true? I don’t know, maybe.)
Yes, obviously the toilets can move. You cannot even begin to fathom what these toilets are capable of.
Looking at Skibidi Toilet for the first time, you might think it was made in a janky 3D engine. And you’re partially right. What you might not realize is that it’s made in Source Filmmaker, a 3D engine developed by Valve in 2012 to make animations with video game assets. You might not realize that the series is littered with video game assets and models from games like Half Life and Counter-Strike, and that it was inspired by animations done with Garry’s Mod.
Source Filmmaker is the logical extension of machinima, e.g., movies shot in video games. While Source Filmmaker is definitively a piece of animation software that happens to run on game assets, machinima even in “real” games is a rich genre. Consider Emesis Blue, a psychological action thriller made and set in the world of Team Fortress 2; Whitepine, a sensitive and artistic period drama/mystery made in Minecraft; and of course, the award-winning documentary Grand Theft Hamlet.
Historically, these all stem from an interesting question: Why would you want to watch someone else play a video game?
A brief history of machinima
This makes more sense then you might think. I think for a lot of us, our first memories of video games were watching someone else play it. Friends. An older sibling. Waiting for your turn on the controller, or handing over the reins to your sibling to see if they can do the hard part for you, or just watching.
It’s oddly enchanting to watch someone else play: you get to see the visuals. If there’s a story, you still get to experience the story. If they’re good at the game, it becomes like watching sport. Earliest preserved game footage – not games, videos of people playing games preserved for reasons other than technical demos of the game itself – are of PVP combat or speedruns, i.e., skill.
But even decades ago, people became interested in games as artistic medium. Telling stories about things that might have happened in the game, but then really getting wacky with it, just using the game as artistic expression.
I think it’s interesting to note different levels of storytelling in this process, all of which are still widespread:
There’s the narrative a game has in the first place. You’re there to rescue the princess, you’re there to slay the princess, whatever. As a viewer, you might have the added narrative layer of the player learning about or reacting to the story, but the root story is the one the game is designed to tell.
Then there are stories invented by the players that still operate under the game’s world and logic.
Then there’s the full abandonment of the game mechanic aside from as stage. Garry’s Mod can be used to make games and is designed to open up this end of the spectrum, and Source Filmmaker completely departs from the game premise – Skibidi Toilet takes place far on this end of the spectrum, maybe even off of it.
Skibidi Toilet remembers its heritage in video games – video game characters and models, the first-person camera angles, the fact that they’re literally shot from a person’s head perspective, guns and weapons in arms akimbo at the side of the screen, enemies bearing down on the POV – these are all familiar video game features. Later, there are HUD overlays. It does not occur to you at first to wonder why you’re seeing it this way.
But Skibidi Toilet has a lot up its titanic sleeves.
The first smoldering clue that this series has something really interesting going on, over the first dozen or so episodes – which is to say, the first few minutes – is the dawning realization that the camera is always diagetic. Every single shot has a camerahead behind it, filming.
With this realization, some of the more inexplicable elements suddenly make sense. The toilets are always lunging straight for the camera because he is an enemy.
Do you need arms to have an arms race?
It’s possible you’re wondering: okay, so that’s the basic plot, but what is Skibidi Toilet, like, about? Does it have themes?
I’m so glad you asked. Skibidi Toilet is about technological escalation during warfare.
The nature of the conflict changes dramatically over the course of the series. Skibidi Toilet is breathtakingly internally consistent about who has what capacity and when.
For instance, perhaps the first technology we see change hands is size. From very early on (even in the first few otherwise dubiously-relevant episodes), we see that there are small toilets and large toilets. There are a few plattoons of regular-sized toilets led by one very big toilet, maybe up to many stories high.
And yet, all of the AV Army we see at first are about human-sized. When the first large camerahead appears, it’s maybe twice as tall as a human, kind of a buff Bigfoot creature. Strong, but not a game-changer. The introduction in Episode 18 of an actual many-stories-tall AV kaiju – pardon me, I’m being told by the loyal soldiers of the Skibidi Toilet Wiki that they’re called “titans” – deeply transforms the battle. By the very next episode, we see cameraheads relaxing while the titan does its work fighting, and into the future, cameraheads seem to go from constantly afraid to living more of a relaxed lifestyle on the winning side. Titans remain a crucial tactic for the rest of the series.
The titans also become the first of a trend of recurring characters, which I suppose makes sense – a few titans are presumably substantial investments. (Obviously, we never get any idea where or how new technologies are invented, or how any of these soldiers are born or created, or where resources come from. It’s not ratfic, it’s Skibidi Toilet. Relax.)
Not all advancements are especially useful. We first see a camera on gangly metal crab-legs in Episode 12, alongside an advancing camera army. It’s a few episodes later when we see toilets on crab legs. The advantage of this is unclear – the toilets already move, and maybe that’s why this doesn’t confer a strong advantage. We see some toilets on crab legs afterwards (maybe they’re going a little faster?), but they’re not uniformly better.
As goes war. Unpowered military gliders offer some unique advantages, like fuel efficiency, deploying troops together rather than dispersed as if landing by parachutes, and being unconstrained by certain aircraft treaties, and multiple countries developed them in World War II. But gliders are not an important part of any military strategy today – they’re just not as good as planes and parachutes and so forth. We tried them out, we went back – the technology is still around, it’s just not optimal. That’s what I see the situation with the crab legs to be.
Far more impactful is the mind-control-parasite strategy. I think this might have been inspired by the AV army’s use of a camera with a toilet base in Episode 16, but it’s the Skibidi Toilets that pioneer the technology: infiltrating a large AV warrior by using a smaller-than-life toilet, living inside the host’s body. (Helpfully indicated to the viewer with crackling lines of electricity around the head of the infected.) The AV Army later develops a crude variation, in which human-sized cameraheads hijack a toilet Titan, but it’s not quite the same. The hijacking of powerful AV titans remains a useful Toilet strategy for the rest of the series.
The AV Army, in response, looks for solutions elsewhere – they invent sound weapons that play the THX riff, disabling both regular toilets and parasitic toilets inside hosts. They also produce a TV-headed woman who teleports, introducing who I believe is the first of the non-titan recurring characters. Interestingly, I think only her or maybe a very small number of other AV warriors can teleport – admittedly breaking the “technological development” pattern, because you would think that if she could do it, others could be taught the skill. They’re all mechanical, right?
This is actually kind of confirmed in the universe – we see AV people both large and small being “repaired” with mechanical tools rather than bandaged by doctors. So maybe there’s some story there, or maybe not. I don’t know. I didn’t check.
Either way, the progression is tightly adhered to, and this is only a tiny smattering of the developments. Weapons and strategies and body forms of both sides expand and diversify over the series. The Toilets even produce some true body horror combatants with the body of a camerahead and the head of a Skibidi Toilet, if you can even imagine such a thing.
At one point, an AV warrior’s arm is ripped off on the battlefield. It detaches an arm from a nearby dead toilet construct and just attaches it onto itself, where it starts working right away. Insofar as Skibidi Toilet has worldbuilding, I think this moment is crucial – it shows the depths to which these two seemingly disparate species are innately interoperable, and goes a long way to explaining the rapid pace of the (to to speak) arms race throughout the series.
This rapid technological exchange has the obvious Doylistic interpretation: it’s more exciting to show people something they haven’t seen before, and the creator gets new ideas the longer the series runs. Also, the entire series is built on “blending components of 3D models together” – see human-toilets, human-cameras. But the attention to detail and consistency? That has to be intentional. Watsonianly, this is a story of two powerful biomechanical species in a technological arms race.
There are a few weapons that emerge later that don’t feel like they follow this pattern, except for in a metatextual way. As the series matures, its aesthetics mature too. I think the artistic high point of this is when we see an AV army champion, facing a toilet squadron, wield a pair of plungers like swords. As far as I recall, we never saw any plungers before this, but it feels, instinctively, like an older and more disciplined form of warfare. We know in our bones that this plunger camera is cool. A real smooth operator.
But down the line, there are just knives. Before this, we saw toilets die to two things: flushing the head, and sort of generically in explosions. But by episode 50 or so, an AV Army guy just stabs a toilet in the head, with a knife. There’s blood (albeit in a 2012-video-game particle-effect-cloud kind of way). In addition to the space-age ray guns or directed sound weapons, realistic guns enter play around this time.
The psychological effect of this is jarring. You are reminded that DaFuq!?Boom! is not under the thumb of any major American television network. I think it’s an interesting artistic choice, but I’m still not sure what to make of it.
Oh, and other hallmarks of war are all over the series. In Episode 21, two cameraheads apparently interrogate a captured toilet in a dark room regarding the location (or… something) about a particular recurring Toilet Titan (this one has the head of the G-man from Half Life. He is called the G-Toilet, according to the Skibidi Toilet Wiki. I mostly didn’t refer to outside information, since I think personal interpretation is part of the fun of such a surreal piece of art, but a friend pointed out that the model is recognizable if you’ve played Half Life, which I haven’t, and I reluctantly admit that “G-Toilet” is a better name than the one I’d come up with, which was “Titan Toilet Richard Nixon.”) Anyway, that’s fucked up, right?
Two cameraheads torture a toilet for information about the Titan Toilet Boss. Or something.
And we watch as the cameramen, in their new hegemony, hound and beat single toilets (who they now outnumber.) They patrol the streets but in a relaxed, this-is-just-my-day-job way. They sit on the empty husks of defeated enemy toilets.
Even in the later episodes, when the apparent primary drivers of the action are huge familiar titans, Skibidi Toilet never quite forgets the little guy. After one brutal toilet attack, the POV camerahead is injured and we see its vision black out… but reawaken, moments later, in an AV hospital ward. There are medical personnel and cameraheads in wheelchairs. We’ve seen titans being repaired but we’ve never seen regular cameraheads being repaired. This too reinforces that the tide is turning in the AV Army’s favor – that it’s now possible to give care and repair to the previously-disposable footsoldiers.
(Does being on the winning side of a war mean regaining your ability to exercise your humanity? Discuss.)
I think my favorite episode is 58, after the toilets have taken the lead.
It features a late-stage-Skibidi Toilet-typical battle involving both smaller combatants and titans. who look cool, and do cool stunts. At the start of the episode, large bladed toilet drives by with a camerahead impaled on one of its sword-arms. (At first, this seems unreasonably cruel, but remember we’ve also seen the AV Army sitting on the husks of dead toilets – is this really any different?)
Anyway, the episode refers back to – almost centering – these three little identical regular cameraheads, clinging to a streetlamp amid the chaos. We’ll never get to know them as individuals. We’ll never even know if we’ve seen them again after this episode. But we are given space to care about their survival and personhood for just a moment.
Wait, maybe you don’t want to watch this
The series does drag. I don’t want to overstate it. The realism is superficial; we have no idea where either of these groups come from, or why they’re fighting. We don’t know how they produce new soldiers, or where they’re fighting, or why they can’t just build one titan the size of the city and be done with it. Often a previously unseen enemy titan will emerge from somewhere at a dire moment and it’s unclear where it came from or how the latest skyscraper-sized Titan Toilet could have remained unnoticed until right now. Doesn’t the AV Army have literal sentient security cameras? How did you miss that, Harold?
We have indications that both sides have culture and internal lives, but we don’t know anything about those. Without a good explanation like “toilet mind control parasites momentarily creating turncoats”, literally every toilet is fighting literally every camerahead – the war is fixed, and the war is absolute.
This gets draining, especially combined with the short-format. See, Skibidi Toilet is highly responsive to the Youtube algorithm. Around the start of Skibidi Toilet, Youtube really liked Shorts (phone-screen-aspect videos under a minute long), and so dozens of episodes are that short. Many are under 30 seconds. The effect of that is that each 30 second episode has to have an entire and complete arc, and the arc usually ends in “a Skibidi Toilet throwing itself disorientingly at the camera.” They are always singing the same song.
I watched it for the first time in one two-hour sitting, and that was probably part of it. I have enough Gen Alpha joie de vivre that I can take a lot of 30-second absurd shorts, but… maybe not that many.
I can’t completely compare it to qntm’s proposed film concept “One Hour Fight Scene”, because Skibidi Toilet has more diversity of setting and arc than that, but the repetitiveness and even the constant escalation is just… grating.
So I’d advise not watching it all at once – but that’s bad advice too, because I discovered that the wordlessness and repetition lends it a dreamlike quality of transience. 24 hours after watching Skibidi Toilet, you’ll be like “what happened last time? Which titan just did what? Have we seen that character before or not?” I legitimately found that taking notes helped. Maybe there’s just no way to comfortably ride this wild steed.
For what it’s worth, Skibidi Toilet is mostly self-aware about its descent into formulaicness, and there are a lot of small moments playing with this that make the series sparkle. When the AV Army steals secret documents from some kind of Toilet research base, the documents… just write out the lyrics of the Skibidi Toilet song in bungled Cyrillic. The plot beat is just that familiar one of stealing big enemy plans. It doesn’t really matter what the plans are, and this deep in, you know this and I know this and DaFuq!?Boom! knows this.
At one point, we see a camerahead scientist “drink” a cup of coffee by dumping it down the front of its shirt.
And later on, a human man apparently representing DaFuq!?Boom! himself shows up in the series – a face we’ve previously only seen as a youtube avatar, suddenly breaking the assumed laws of the narrative by appearing in his own creation. I won’t spoil any more, but it’s a buck fucking wild ride.
I don’t want to assure you that it’s worth it. I don’t know you. I won’t say that. At the end of watching some small toilets fight some small camera guys, you’ll be rewarded with a much bigger toilet fighting a much bigger camera guy. Does that sound fun? Hey, if it does, I know a series you might like.
Found footage and horror
Skibidi Toilet is not really a horror series, but it takes a lot of its beats and inspiration from horror.
The oldest kind of internet-original video horror is screamers. It’s the cheapest and easiest way to make horror – take a pretty normal piece of footage or imagery, let people watch it for a few minutes, then BAM! Sudden cut to a creepy face. It’s the digital equivalent of yelling “BOO” behind someone’s back, automated for your inconvenience. Ghost Car [content warning: bro, read the room] is a classic of the genre, 19 years old and with 41 million views at the time of writing. The hook of early episodes of Skibidi Toilet is not much different from 19 years ago – some weird stuff happens and then a distorted face flies real quick at your screen.
DaFuq!?Boom! has stated that he was literally inspired by toilet-related nightmares, so the surreality and sense of panic at the outset make a lot of sense. But as the plot develops, Skibidi Toilet starts taking influence from a wider variety of genres, especially horror subgenres.
One of these is found footage. We’ve touched on the cameraheads and their diegetic filming already – we also see alterations to the footage, like a cameraman falls and the footage goes wavery for a second, or a camerahead is hit by a beam weapon and the footage distorts.
Horror that pretends (at some level) to be reality is not new – how many ghost stories are intentionally told as “no, my cousin’s friend’s friend said this really happened to her”? Dracula in 1897 and The Phantom of the Opera in 1910 are both framed as letters and diaries and news reports.
Skibidi Toilet is obviously not going full Blair Witch Project or War of the Worlds in terms of trying to convince us the story is real, but just in the footage, the full commitment to the bit that all of this is being witnessed by a person(-thing) really adds intrigue and serious sophistication. The shot will end when the POV camerahead either chooses to end the shot, or when it dies. It builds tension by default. I think there’s maybe one moment in the whole series when the filming camerahead dies mid-episode and we are swapped without context to another camerahead. Everything else flows.
How any of this footage gets to us, relatedly, is unclear. It’s not so found-footage as to say “here are the tapes I found in a box in the woods” or “we now present footage from the Joint War Archive, documenting our shared dark history prior to the Toilet-AV Peace Treaty of 2065.” (But that’s pretty good – hey, DaFuq!?Boom!, if you’re reading this, feel free to use that.) But I like to imagine that a peak virtue among AV society is the act of witnessing, and that having and curating this footage of dark moments is good to them. That might explain why so many of them wade into battle, why there’s always someone watching from a good spot, why so many of them stay under fire until the last moment.
There are also underground institutional labs that strike me as borrowed from horror – your Half Lifes, your Resident Evils, your Stranger Things, your SCP Foundations. (Given that Skibidi Toilet borrows other assets from Half Life, it’s kind of the obvious thing to go for.) We see surprisingly little combination between these laboratories and the technological arms race, although I think it’s implied that many new developments come out of these labs. These environments connect more to the post-apocalyptic elements of the series and the vestiges of humanity and the possible origin of the Skibidi Toilets and the AV Army both – although any real answers remain beyond me, if they exist at all.
The real culture war
I didn’t expect, before starting the series, that the eponymous Skibidi Toilets would be the villains. But the existence and narrative role of the AV Army opens up a very interesting series of questions.
What fraction of the viewers of Skibidi Toilet have ever worked with a TV camera? Or a regular camera, for that matter? Wouldn’t they just do all of that on a phone?
I notice that the AV Army doesn’t have any smartphone-heads – or laptop-heads, for that matter. Even flatscreen-heads are rather thin on the ground. They use an older aesthetic: steely surveillance cameras, CRT televisions, tape video recorders or film cameras. They wear suits. Their theme song – only heard a few times, possibly because of Youtube copyright strikes, but distinct – is an echoey version of 80s hit Everybody Wants to Rule the World.
Their enemies are, of course, the toilets: frightening, gross, offensive, always lunging at the viewer, always singing their song that has certainly become repetitive by the 20th time (and you will not escape Skibidi Toilet having heard the Skibidi Toilet song only 20 times.)
Even Source Filmmaker is a millennial’s animation tool. DaFuq!?Boom! isn’t a babe in arms, he has years of machinima experience.
People drag Skibidi Toilet as trash, as brainrot, as the meaningless poison of the youth du jour. Do they see the war? The uncouth screaming toilets versus the cool suits of the older generation? I have no idea how intentional this was, but it just sits with me.
A friend, who is much closer to the usual Skibidi Toilet viewing age than I am, described that the cameraheads evoked a sense of omnipresent surveillance that rang true to his life. I suppose it’s true of all of us, even if the older generations are less aware of it. Everybody has a camera on them at all times. Everybody has a screen on them at all times. The AV Army may be our heroes but they’re also literally a surveillance state. We watch through the eyes of the smallest and weakest among them as they die repeatedly.
I don’t know. I just think it’s an interesting angle on the show, intentional or not.
There’s one predecessor series, the DaFuq series, which feels to me like the real precursor for Skibidi Toilet. This series involves clips of regular scenes – people shopping, walking in a park, etc – until every model suddenly distorts, and there are screams as they’re rearranged into a surreal hybrid tableau.
This feels like the invocation of a thing that I’m sure machinima artists have done since the beginning – just played with the models, used them as toys, as sandboxes, made monstrosities just for the hell of it while learning the tools. DaFuq!?Boom! renders these dollhouse abominations as growing from realistic scenes, thus turning them into surreal horror-comedy. I am absolutely certain this is what Skibidi Toilet grew out of.
There’s a genre of media on the internet where the creator clearly didn’t intend for a goofy new project to grow into an epic, but it did. Griffin Mcelroy recorded The Adventure Zone, a game of Dungeons and Dragons with his brothers and father, as a podcast, which they had intended as an easy interlude to their regular podcast while one family member was on paternity leave. But instead the game spiraled out for months, developing real characterization, narratives, a universe-bending arc, and it became a beloved franchise now adapted as a comic book. He described the unexpected whirlwind as “a car that learned to fly.”
Now, I’m sure that novelists have been starting what they think is going to be a short story and what spirals into, I don’t know, Moby Dick, or The Bible, since the beginning of time. But crucially, in novels, once you figure out it’s going to be a big deal, you can go back and rewrite the beginning to fit with the quality and scope of your vision.
But barely-planned epic serial media, which the internet is rife with, doesn’t let you do that. The beginning is already out there.
This means:
A) If the authors improve over time, the beginning will still be rough. You can watch Skibidi Toilet grow. Literally: in episode duration and in physical size (it started as a series of youtube shorts and thus the first few dozen episodes are in the upright-phone-screen aspect ratio, but past episode 38 all videos are full-screen.) Figuratively: in animation and visual quality, in coherence, there’s a plot, there’s characters, etc.
B) Relatedly, the authors are stuck with whatever stupid gags they started out with. They’re stuck with wizards named Taco, with teenagers obsessed with Nicholas Cage, with Minecraft nations named “L’manberg” because they didn’t have any women and they wanted to sound European, with toilets with human heads sticking out of the bowls that you can kill by flushing them.
And it is so, so beautiful. To wax philosophic for a moment, I don’t think you’ve truly appreciated art until you’ve been swayed to your very soul by the inner turmoil of Taako the Wizard or the sad little pixels of a Minecraft face or the fact that the Nicholas Cage teen stopped liking Nicholas Cage or the camera-headed guys giving each other thumbs-up after flushing toilet-men – by something so dumb it’s embarrassing. Yes, it’s stupid. It’s so very, very stupid. A novice home-cooked meal or an inadvisable crush or an inside joke can also be stupid. They can also be everything.
Past the veil of shame is where the dark, gross, raw workings of the heart lie. Meet me there.
Anyway, another interesting thing about Skibidi Toilet is that almost all of its assets are recycled from elsewhere.
Take the AV army. All of the models are other people’s – suited figures and AV equipment. DaFuq!?Boom! cites the creators in his video description. TVheads are a surprisingly common modern internet chimera. They’re not especially common characters in any particular piece of media, but look it up and you’ll find people cosplaying and making art of TVheads. They might have stemmed from people inspired by the 2000 character Canti, a robot with a TV-like screen for a head in the anime FLCL. But the modern suited TVhead is now a fully separate species of cryptid. Yoink!
Probably the earliest camera-headed character appeared in a series of frankly awesome 2007 Japanese PSAs against movie theater piracy, in which dancing, suited, camera-headed people(?) dance and illegally film movies. Oops! Culture has been changed forever!
Interestingly, the diagetic camerahead – a human with supernatural camera head or features who films relevant parts of the series – also plays a minor but impressive role in a legendary 2010-2019 slenderman youtube series and alternate reality game. In EverymanHYBRID, the supernatural villain character (uh, the one who’s not slenderman), the one who’s been hijacking the main team’s youtube channel, also begins hijacking human victims and using them as living video cameras. We never see a camerahead in EverymanHYBRID – it’s a live-action series on a shoestring budget that plays hard for realism – but we do see their camerawork, and we see the main cast react with horror to the thing shooting the picture. It directly asks the question “who’s behind the camera” with a horror flavor, which is of great thematic interest in EverymanHYBRID and which I was surprised to see echoed in Skibidi Toilet.
(I have no reason to think DaFuq!?Boom! has watched EverymanHYBRID, but it’s a very interesting parallel.)
In the first version of this review, I wrote that speakerheads don’t have much in the way of cultural context, but how could I forget Sirenhead? This creepy monster invented by artist Trevor Henderson is a slenderman-esque figure with multiple gaping fleshy megaphone heads, that like the cameraheads, was appropriated by the internet as a folk villain.
Skibidi Toilet’s speakerheads are the domesticated version – they’re just suited humanoids with speaker clusters for heads, in and among the TV heads and cameraheads. The speakerhead titans in Skibidi Toilet are major characters, apparently developing out of the AV Army’s experiments with sound-based energy weapons.
These more human speakerheads, and the idea of cameraheads and TVheads and speakerheads all forming a natural alliance based on shared structure? I think that’s all pure innovation on DaFuq!?Boom!’s part.
(By the way, Biser King is Bulgarian and Timbaland is American, and the remixed song appears to have become viral in Turkey before being used as a video soundtrack by American Tiktokker, Paryss Bryanne, which in turn inspired Skibidi Toilet creator DaFuq!?Boom!, who is Georgian (as in country of Georgia) – thus making an unusual international journey even before reaching the world’s ears as THE Skibidi Toilet song.)
My early interest in tech and tech culture came out of the open source movement, and I have an admittedly rosy-eyed optimism around things like creative commons and free cultural exchange. The machinima community follows this spirit 100%: adapt what you want, build something new, share it around. While I’d never thought about it before, Tiktok culture loves to do this. And Skibidi Toilet rejoices in it too – it is an exquisite collage of borrowed characters, models, songs, and effects all repurposed in creative new ways. It’s a hit kid’s show that’s absolutely unbeholden to any studio or copyright law or content standard other than the bare minimum enforced by youtube. It’s a car that learned to fly. And it’s glorious, and it’s clever, and most importantly, it’s an absolute trip.
The late game
I will say that over time, along with more beautiful atmospheric animations and longer episode lengths, the series Marvelfies. It’s easy to see why – from very early on, it was about escalating fights and drama. So why not scale it to its extreme: huge clashes between titans, dramatic soundtracks and panning action shots. Get some revelations and some shadowy underground bosses and some generic one-liners in there too. Why not?
I personally draw the line at the one-liners – it’s so surprising to hear speech in Skibidi Toilet that I feel it should be conserved or avoided entirely. But as of the most recent episodes, the plot is so convoluted that it’s now necessary to verbally explain a bare minimum of what’s going on.
(…Okay, when I say it like that, that’s actually a really high bar that basically no other story meets. Fair enough, Mr. Boom.)
And the series loses some creativity on the way, I think – not all of it, but it has clearly turned from a post-apocalyptic psychological horror franchise with war elements into an action franchise, and I preferred the genre mixing pot.
One notable plot point that I have mixed feelings about (and if this is partially due to the fact that I was four drinks in at this point when I first saw it and completely missed what was going on, it’s surely impossible to know) – is that a force of alien Space Toilets arrive. They have their own space-age technology and aesthetics – red lights, drone-like hover capacity, fancy shields, the works. At first, they seem to be allied with the Skibidi Toilets, as one might expect; however, the alliance fractures. As of now, the Skibidi Toilets have now teamed up with the AV Army against the powerful alien forces.
And, like, I guess? It’s very Watchmen. It feels like aw, okay, sure, now you have fans of both sides and lines of action figures sold at Target, they have to team up as heroes against a convenient new enemy. Sure. Yes, obviously I bought one.
I’d be more invested in the team-up plotline if we saw either more or less of whatever humanity the Skibidi Toilets have – while we’ve seen lots of humanizing interactions between AV Army members, even the rudiments of Skibidi Civilization are mysterious to us. On the other hand, being forced to cooperate with a nightmarish creepypasta jumpscare entity that has at most a semblance of relatability would be very interesting too. Either way, we have, alas, seen very little of the timbre of the AV Army-Toilet alliance.
More interesting is the side plot in which human beings have appeared – survivors, apparently, people who have been holed up since the fall of their world, their presence further suggesting that the entire series has taken place on some post-catastrophe Earth. They’re with the alliance too, and they’re weak and underpowered in this new paradigm.
Mostly the series has drifted away from surreal comedy-horror and into solely epic action scenes, with occasional difficult-to-parse intrigue. A return to form would not be amiss. But it still has a lot of heart in it, a frankly wild amount of implicit worldbuilding, and as a visual spectacle it’s only growing over time. I, personally, am curious to see if the AV-Toilet alliance holds, and if the human survivors will find any place in the world to come.
I hope we all find a place in the world to come.
Final rating
5/10. I have no idea how this was monetized and I hope the creator makes ten million dollars off it. If you’re going to watch the whole thing at once, I recommend being drunk.
This review was written as an entry for Astral Codex Ten‘s 2025 “Anything-But-A-Book Review” contest – it didn’t make the finalists, but watch for those on ACX in the coming days.
Thank you Nova for suggesting the title of this post.
Support Eukaryote Writes Blog on Patreon.Sign up for emails for new posts in the blog sidebar.
Remember early 2020 and reading news articles and respected sources (the WHO, the CDC, the US surgeon general…) confidently asserting that covid wasn’t airborne and that wearing masks wouldn’t stop you from catching it?
Man, it’s embarrassing to be part of a field of study (biosecurity, in this case) that had such a public moment of unambiguously whiffing it.
I mean, like, on behalf of the field. I’m not actually personally representative of all of biosecurity.
I did finally grudgingly reread my own contribution to the discourse, my March 2020 “hey guys, take Covid seriously” post, because I vaguely remembered that I’d tried to equivocate around face masks and that was really embarrassing – why the hell would masks not help? But upon rereading, mostly I had written about masks being good.
The worst thing I wrote was that I was “confused” about the reported takes on masking – yeah, who wasn’t! People were saying some confusing things about masking.
I mean, to be clear, a lot of what went wrong during covid wasn’t immediately because biosecurity people were wrong: biosecurity experts had been advocating for years for a lot of things that would have helped the covid response (recognition that bad diseases were coming, need for faster approval tracks for pandemic-response countermeasures, need for more surveillance…) And within a couple months, the WHO and the Surgeon General and every other legitimate organization was like “oh wait we were wrong, masks are actually awesome,” which is great.
Also, a lot went right – a social distancing campaign, developing and mass-distributing a vaccine faster than any previous vaccine in history – but we really, truly dropped the ball on realizing that COVID was airborne.
In his new book Air-borne: The hidden history of the air we breathe, science journalist Carl Zimmer does not beat around this point. He discusses the failure of the scientific community and how we got there in careful heartbreaking detail. There’s also a lot I didn’t know about the history of this idea, of diseases transmitting on long distances via the air, and I will share some of it with you now.
Throughout human history, there has been, of course, a great deal about confusion and debate about where infectious diseases came from and how they were spread, both before and to some extent after Louis Pasteur and Robert Koch et al illuminated the nature of germ theory. Germ theory and miasma theory were both beloved titans. Even after Pasteur and Koch had published experiments, the old order, as you may imagine, did not go quietly; there were in fact series of public debates and challenges with prizes and winners that pitted e.g. Pasteur up against old standouts of miasma theory.
One of the reasons that airborne transmission faced the pushback it did is that it was seen as a waffley compromise of a return to miasma theory. What, like both a germ and the air could work together to transmit a disease? Yeah, sure.
Airborne transmission was studied extensively in the 1950s. It eventually became common knowledge that tuberculosis was airborne. That other diseases, like colds and flu and measles, could be airborne, was the subject of intense research by William and Mildred Wells, whose vast body of work included not only proving airborne transmission but experimenting with germ-killing UV lights in schools and hospitals — and who remain virtually unknown to this day.
Let us acknowledge a distinction often made between droplet-borne diseases, where heavy wet particles might fly from a sneeze or cough for some six feet or so, to airborne diseases, which might travel across a room, across a building, wafting about in the air for hours, et cetera. This distinction is regularly stressed in the medical field although it seems to be an artificial dichotomy – spewed particles seem to be on a spectrum of size and the smaller ones fly farther, eventually becoming so small they’re much more susceptible to vagaries in air currents than to gravity’s downward pull. Droplet-borne diseases have been accepted for a long time, but airborne diseases were thought by the modern medical establishment to be very rare.
(I forget if Zimmer makes this point, but it’s also easy to imagine how it’d be easier for researchers to notice shorter-distance droplet-borne transmission – the odds a person comes down with a disease relates directly to how many disease particles they’re exposed to, and if you’re standing two feet away from a coughing person, you’ll be exposed to more of the droplets from that blast than if you’re ten feet away. Does that make sense? Here’s a diagram.)
Aerosols disperse from their source over distances.
(But that doesn’t mean that ten-foot transmission will never happen. Just that it’s less likely.)
Why didn’t the Wells’ work catch on? Well, it was controversial (see the ‘return to miasma’ point above’), and also, they were just unpleasant and difficult to work with. They were offputting and argumentative. Also Mildred Wells was clearly the research powerhouse and people didn’t want to hire just her, for some reason.* Their colleagues largely didn’t want to hire and fund them or to publish their work. We have a cultural concept of lone genius researchers, but these are, in terms of their impact, often fictional – science is a broadly collaborative affair.
The contrast in e.g. Koch and Pasteur’s status vs. William and Mildred Wells made me think about the nature of scientific fame. I wonder if most generally-famous scientists were famous in their lifetimes too. Koch and Pasteur were. Maybe most famous scientists are also famous because they’re also good science communicators. I’m sure that also interplays with getting your ideas out into the world – if you can write a great journal article that sounds like what you did is a big deal, more people will read it and treat it like a big deal.
The Wells were not a big deal, not in their day nor after. Their work, studying disease and droplet transmission and the possibility of UV lamps for reducing disease transmission (include putting lamps up in hospitals and schools), struggled to find publication and has only recently been unearthed as a matter of serious study.
Far UV lamps are the hot new thing in pandemic and disease response these days. Everyoneistalkingaboutthem.
There’s variations and nuance, but the usual idea works like this: you put lamps that emit germ-killing UVC light up in indoor spaces where people spend a lot of time. UVC light can causes skin cancer (albeit less than its higher-energy cousin, UVB). But you can just put the lamps in ventilation systems or aimed up at the ceilings, where they don’t point at people or skin but instead kill microbes in the air that wafts by them. Combined with ventilation, you can sterilize a lot of air this way.
William and Mildred Wells found results somewhere in between “positive” and “equivocal” – the affect being stronger when people spent more of their day under the lamps, e.g., pretty good in hospital wards and weaker in schools.
They’re not too expensive and could be pretty helpful, especially if they became de facto in places where people spend a lot of time – and especially in hospitals. Interest in this is increasing but there’s not much in the way of requirements or incentives for any such thing yet.
*Sexism. Obviously the reason is sexism.
The other heroes of the book are the Skagit Valley Chorale. In March 2020 a single Skagit Valley Chorale choir rehearsal transmitted multiple fatal covid cases during a single choir practice. Afterwards, the survivors worked with researchers, who figured out where everyone was standing, where points of contact were, did interviews and mapping and figured that there had been no coughing or sneezing, that the disease had in fact been flung at great distances just by singing – that it was really airborne. (There were other studies in other places indicating the same thing.) But this specific work of contact tracing was a focus and was instrumental and influential, and cooperation between academic researchers and these grieving choir members formed an early, distinct piece of evidence that covid was indeed airborne.
I think being part of research like this – an experimental group, opting into a study – is noble. It’s selfless, and what a heroic and beautiful thing to do with your grief and your suffering, to say: “Learn everything you can from this. Let what happened here be a piece in the answer to it not happening again.”
(Yeah, I got dysentery for research, but listen, nobody in the Skagit Valley Chorale got $4000 for their contributions. They just did it for love. That’s noble.)
There was also a cool thread of the story that involved microbiologists like Fred Meier and their interactions with the early age of aviation – working with Lindbergh and Earhart and balloons and the earliest days of commercial aviation to strap instruments to their crafts and try to capture microbes whizzing by.
And they found them – bacteria, pollen, spores, diseases, algaes, visitors and travellers and tiny creatures that may have lived up their all their lives. Another vast arm of the invisible world of microbes.
I’ve been interested in the mechanics of disease transmission for almost as long as I’ve been interested in disease. In freshman year in college I tried an ambitious if bungled study on cold and flu transmission in campus dorms. (That could have been really cool if I’d known more about epidemiological methods or at least been more creative about interpreting the data, I think. Institutions are famously one of the easier places to study infectious diseases. Alas.) Years later I tried estimating cold and flu transmission in more of an EA QALY/quantifying-lost-work days sense and really slammed into the paucity of transmission studies. And then covid came, and covid is covid – we probably got the best data anyone has ever gotten on transmission of an airborne/dropletborne disease.
More recently, I’ve been doing some interesting research into rates and odds of STD transmission, and there’s a lot more there: there’s a lot of interest and money in STD prevention, and moreover, stigmatized as they are, it’s comparatively easy to determine when certain diseases were caught. They transmit during specific memorable occasions, let’s put it like that.
For common air- or droplet-borne diseases? Actual data is thin on the ground.
I think this is one of the hard things about science, and about reasoning in and out of invisible, abstract worlds – math, statistics, physics at the level of atoms, biology at the level of cells, ecology at the level of populations, et cetera. You know some things about the world without science, like, you don’t need to read a peer-reviewed paper to know that you don’t want to touch puke, and you don’t need to consult with experts in order to cook pasta. The state of ambient knowledge around you takes care of such things.
And then there’s science, and science can tell you a lot of things: like, a virus is made of tiny tiny bricks made of mucus, and your body contains different tiny virus detectors (also themselves made of mucus), and we can find out exactly which mucus-bricks of the virus trigger the mucus-detectors in your body, and then we can like play legos with those bricks and take them off and attach them to other stuff. We know about dinosaurs and planets orbiting other stars.
And science obviously knows and tells us some useful stuff that interacts with our tangible everyday world of things: like, you can graft a pear tree onto a quince tree because they’re related. A barometer lets you predict when it’s going to rain. You can’t let raw meat sit around at room temperature or you might get a disease that makes you very sick. Antibiotics cure infections and radios, like, work.
And then there’s some stuff that’s so clearly at this intersection that you might assume it’s in this domain of science. Like, we know how extremely common diseases transmit, right? Right?
It used to blow my mind that we know enough about blood types to do blood transfusions and yet can’t predict the weather accurately. Now it makes visceral sense to me, because human blood mostly falls into four types relevant to transfusions, and there are about ten million factors that influence the weather. (Including bacteria.)
Disease transmission is a little bit like predicting the weather, because human bodies and environments are huge complicated machines, but also not as complicated, because the answer is knowable – like, you could do tests with a bunch of human subjects and come up with some reasonable odds. We just… haven’t.
Actually, let’s unpack this slightly, because I think it’s easy to assume that airborne (or dropletborne) disease transmission would be dirt cheap and very easy to study experimentally.
To study disease transmission experimentally, you need to consider three things (beyond just finding people willing to get sick):
First, a source of infection. If you’re trying to study a natural route of infection like someone coughing near you, you can’t just stick people with a needle that has the disease – you need a sick person to be coughing. For multiple reasons, studies rarely infect a person on purpose with a disease, let alone two groups of people via different routes (the infection source and the people becoming infected) – you might need to find a volunteer naturally sick with the disease to be Patient Zero.
Second, exposure. People are exposed to all sorts of air all the time. If you go about your everyday life and catch a cold, it’s really hard to know where you got the cold from. You might have a good guess, like if your partner has a cold you can make a solid statistical argument about where you were exposed to the most cold germs – or you might have a suspicion, like someone behind you on the bus coughing – but mostly, you don’t know. A person in a city might be exposed to the germs of hundreds on a daily basis. In a laboratory, you can control for this by keeping people isolated in rooms with individually-filtered air supplies and limited contact with other people.
Third, when a person is exposed to an infectious disease, it takes time to learn if they caught it or not. The organism might get fought off quickly by the body’s defenses. Or the organism might find a safe patch of tissue to nestle in and grow and replicate – the incubation period of the infection. It’ll take time before they show symptoms. Using techniques like detecting the pathogen itself, or detecting an immune response to the pathogen, might shave off time, but not a lot, you still have to wait for the pathogen to build up to a detectable level or for the immune response to kick in. Depending on the disease, they also may have caught a silent asymptomatic infection, which researchers only stand a chance of noticing if they’re testing for the presence of the pathogen (which depending on the pathogen and the tests available for it, might entail an oral or nasal swab, a blood test, feces test…)
So combine these things – you want to test a simple question, like “if Person A who is sick with Disease X coughs ten feet away from Person B, how likely is Person B to get sick?” The absolute best way to get clean and ethically pure data on this is to find a consenting Person A who is sick with the flu, find a consenting Person B (ideally who you are certain is not already sick, perhaps by keeping them in an isolated room with filtered air beforehand for the length of the incubation period), have Person A stand ten feet away and cough, and then sweep Person B into an isolated room with filtered air for the entire plausible incubation period, and then see if they get sick, and then have this sick person cared for until they are no longer infectious.
And then repeat that with as many Persons B as it takes to get good data – and it might be that only, like, 1% of Persons B get sick from a single sick person coughing 10 feet away from them. So then you need, I don’t know, 1000 Persons B at least to get any decent data.
It’s not impossible. It’s completely doable. I merely lay this out so that you can see that producing these kinds of basic numbers about disease transmission would instantly entail a lot more expense and human volunteers than you might think.
A friend of mine did human challenge trials studying flu transmission, and they did it similarly to this – removing the initial waiting period (which is fair, most people are not incubating the flu at any given moment) and with more intense exposure events, with multiple Persons B in a room actively chatting and passing objects around with a single Person A for an hour, and then sending Persons B to a series of hotel rooms for a few days to see if anyone got sick.
(What about going a step further: just having Person A and Persons B in a room, Person A coughs, and then send Persons B home and call them a few days later to ask about symptoms? You could compare this to a baseline of Persons C who were not in a room with a Person A coughing (“C” for “control”). Well, I think this would get you valid and usable numbers, but exposing people to infectious diseases that could then be freely passed on to nonconsenting strangers is considered a “bioethics no-no” – and so researchers have, to my knowledge, mostly not tried this.)
(Maybe someone did that in the sixties. That seems like something they’d have done back then.)
The point is, it’s like, expensive and medium hard to study airborne disease transmission experimentally. Adjust your judgment accordingly.
Anyway, fascinating book about the history of the history of that which you think might be better understood by virtue of being a life-and-death matter millennia old, but which is, alas, not.
Here are some questions I was left with at the end of the book:
What influences whether pathogens are airborne-transmissible? Does any virus or spore coughed up from the lungs have about the same chance of becoming airborne, or do other properties of the microbe play a role? (I was hoping the book would explain this to me, but I think the research here may not exist.)
Zimmer is clearly pro-far-UV but the Wells’ findings on far UV lamps in schools was in fact pretty equivocal – do we have reason to think current far UV would fare better? (I know I linked a bunch of write-ups but I’m not actually caught up on the state of the research.)
Some microbes travel for long distances, hundreds of miles or months, while airborne. Often high in the earth’s atmosphere. How are these microbes not all obliterated by solar UV?